Gemma 4 Explained: Google's New Direction for Open Models
Google released Gemma 4 on April 2, 2026. Based on the official release page, Google Blog, and Hacker News discussion, this article breaks down model sizes, the Apache 2.0 license, long context, multimodal support, and why local deployment matters.

On April 2, 2026, Google officially released Gemma 4. If we had to summarize this launch in one sentence, it would be this: Gemma 4 is not just another routine update with slightly larger parameter counts. It is Google resetting the tone of its open-model strategy around agentic workflows, local execution, multimodal input, and a more permissive Apache 2.0 license.
Based on official materials and the Hacker News discussion, this article focuses on four practical questions:
- What exactly is Gemma 4, and what changed compared with earlier generations?
- Which use cases fit each of the four model variants?
- How should we read the official benchmarks, and what should we avoid overinterpreting?
- Is Gemma 4 worth tracking right now for developers and engineering leaders?
What Is Gemma 4?
According to the official Google DeepMind page, Gemma 4 is a family of open models "built from Gemini 3 research and technology" and designed around intelligence per parameter. In other words, the goal is to get as close as possible to frontier-model capability while keeping hardware costs more manageable.
Unlike many open models that mainly emphasize chat performance, Google is very explicit about how it positions Gemma 4:
- For advanced reasoning
- For agentic workflows
- For local and edge deployment
- For multimodal understanding and longer-context processing
That means Gemma 4 is not just trying to be "a usable open-source alternative." Google is trying to cover an entire product path that stretches from phones and IoT devices to developer workstations.
How Should You Choose Among the Four Variants? Positioning Matters More Than Raw Parameters

Google released four variants this time: E2B, E4B, 26B MoE, and 31B Dense.
| Model | Official positioning | Best fit |
|---|---|---|
| E2B | Maximum compute and memory efficiency | Phones, edge devices, offline lightweight apps |
| E4B | Lightweight multimodal support with low latency | Local assistants, voice or vision entry points, small on-device products |
| 26B MoE | More focused on speed and agentic workflows | Local inference, tool use, developer workflows |
| 31B Dense | More focused on quality and fine-tuning potential | Research, fine-tuning, complex reasoning, and coding tasks |
From the official description, these four models actually split into two broader groups.
There is also one naming detail worth explaining on its own: in E2B, the E stands for Effective as in Effective 2B. Google states this directly in the Gemma 4 announcement blog, and it differs from the more familiar naming convention that only highlights total parameter count.
What this naming is trying to emphasize is not simply "how many total parameters physically exist," but what effective model scale participates in real inference. For developers, that distinction matters because it is much closer to real deployment constraints such as resource usage, memory pressure, and on-device feasibility, instead of being just a convenient comparison label.
Based on Google's earlier documentation for Gemma 3n, the E prefix was also used to indicate that the model can run at a lower effective parameters scale. In the context of Gemma 4, E2B and E4B should therefore be understood as models that prioritize runtime efficiency and device fit, not just "larger total parameter counts."
E2B and E4B: Edge First
On the official site, Google DeepMind describes E2B and E4B as models built for mobile and IoT devices. Google highlights that these models can run offline on devices such as phones, Raspberry Pi, and Jetson Orin Nano, with low latency as a key selling point.
Two things matter most here:
- They are not text-only models. Google says the full family supports image and video understanding, while E2B and E4B also support native audio input.
- They are not just tech demos. When a model is designed from the ground up for mobile and edge deployment, it becomes much more attractive for privacy-sensitive, local-processing, and unstable-network scenarios than a large model that merely happens to be compressible enough to run.
26B MoE and 31B Dense: Workstations and Local Servers First
The larger models look more like Google's answer to the question of what a high-performance local open model should be.
According to the Google Blog:
- 26B uses a Mixture of Experts architecture, activating only part of the total parameter set during inference, with more emphasis on latency and efficiency.
- 31B uses a Dense architecture, placing more emphasis on raw quality and value as a fine-tuning base.
- Unquantized bfloat16 weights can fit on a single 80GB H100.
- Quantized versions target consumer GPUs, local IDEs, coding assistants, and agent workflows.
If the question is whether a locally run coding assistant can be practical, 26B and 31B are more important to watch than the smaller models.
The Four Most Important Signals from This Release
1. The Apache 2.0 License May Be the Biggest Change of All
The official blog clearly states that Gemma 4 now ships under an Apache 2.0 license. For many teams, that matters even more than the benchmark charts.
Why? Because one of the biggest concerns around so-called open models has always been:
- Can we use it commercially?
- Can we build on top of it with confidence?
- Can we deploy it inside our own infrastructure for the long term?
- Will the license become a compliance risk later?
At least from an engineering adoption perspective, Apache 2.0 gives a much clearer answer. Teams still need to manage deployment, safety, data handling, and output responsibility on their own, but the licensing friction is clearly lower.
The Hacker News thread shows the same sensitivity. One of the phrases that appeared repeatedly in highly upvoted comments was: "Apache 2.0 is a big shift."
2. Agentic Workflows Are No Longer a Bonus Feature. They Are the Main Narrative
Google repeatedly frames Gemma 4 around agentic workflows, and the official copy explicitly calls out:
- Native function calling
- Structured JSON output
- Native system instructions
- Better support for models working together with external tools and APIs
That tells us Google is not treating Gemma 4 as a pure chat model. It is positioning it as an open foundation that can be embedded into workflows, toolchains, and product logic.
If your project is moving in any of these directions, Gemma 4 becomes much more relevant:
- Local coding assistants
- Internal enterprise automation agents
- Document processing and structured extraction
- Multi-step workflows that require offline or tightly controlled inference
3. "Multimodal + Long Context + Multilingual" Is a Combined Strategy
Another standout aspect of Gemma 4 is not any single feature by itself, but the fact that all of these capabilities are being packaged into a relatively deployable open-model family:
- Multimodal: image and video understanding across the whole family
- Audio input: native support on E2B and E4B
- Long context: 128K on edge models and up to 256K on larger models
- Multilingual: Google says the native training data covers 140+ languages
Taken together, this means Gemma 4 is not just "an open-source chatbot base model." It looks more like a component library for building real applications.
Consider a practical example: if you want to build a local knowledge assistant that needs to read long documents, handle OCR or image understanding, and later plug into a voice interface, Gemma 4 presents a more complete roadmap than a traditional single-modality small model.
4. Google Is Clearly Strengthening a Local-First Open-Model Narrative
The official blog repeatedly emphasizes that Gemma 4 can run on:
- Android devices
- Raspberry Pi
- Jetson Orin Nano
- Developer laptops and workstations
- Cloud production environments
The message behind that is clear: Google does not want Gemma 4 to be seen as an open model that is only interesting in the cloud. It wants Gemma 4 to become part of local-first AI.
That creates two immediate attractions for developers:
- Privacy and data control: In OCR, translation, internal document Q&A, and code analysis workflows, some teams simply do not want to send data to a third-party API.
- Cost and latency: Once a workflow is stable and the model is good enough, local inference can be easier to control for frequently repeated tasks.
The Official Benchmarks Look Strong, but How Should You Read Them Without Getting Misled?
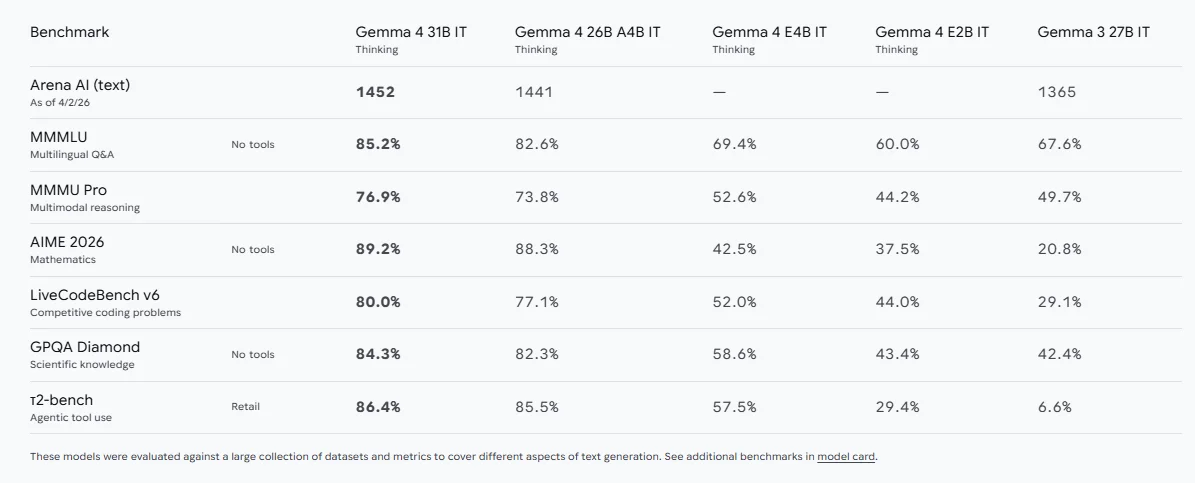
The official Google DeepMind page lists several metrics, including:
- Arena AI (text): 31B IT Thinking at 1452
- MMMLU multilingual QA: 31B at 85.2%
- MMMU Pro multimodal reasoning: 31B at 76.9%
- AIME 2026 math: 31B at 89.2%
- LiveCodeBench v6: 31B at 80.0%
- tau2-bench retail tool use: 31B at 86.4%
At a trend level, Google's message is straightforward:
- 31B and 26B are no longer merely "good enough." On many tasks, they are competing near the front of the pack.
- E2B and E4B are not just lightweight models. They are trying to preserve reasoning and multimodal capability inside a much smaller footprint.
- Gemma 4 is no longer selling itself primarily as a text-chat model. Reasoning, code, and tool use are now part of the value proposition.
But one caution matters here: benchmarks can show a model's ceiling and direction, but they do not automatically translate into production value.
This also showed up clearly in the Hacker News discussion. Some comments pointed out that public benchmarks can be useful, but they do not always match real-world usage, and the final answer still depends on private evaluation against your own tasks.
That is a very practical way to think about it. For teams, the more meaningful comparisons are:
- Task success rate
- Human rework rate
- Tool-calling stability
- Cost and speed under long-context workloads
- Whether capability loss after quantization is still acceptable
What Real Concerns Showed Up in the Hacker News Discussion?
At the time of writing, on April 3, 2026, the Hacker News thread showed about 1211 points and 360 comments. From the discussion itself, community attention seemed to cluster around four areas.
1. The License Change Matters More Than Many People Expected
Several comments directly treated Apache 2.0 as one of Gemma 4's biggest selling points. The reason is simple: the open-model community has never lacked models that are merely "downloadable." What it has lacked is a license that genuinely reduces commercial and integration friction.
2. The Room for Local Deployment Feels Large
You can clearly see a recurring class of use cases in the discussion:
- Local OCR
- Document processing
- Translation
- File organization
- Coding assistance
- Private-data workflows
This lines up with Google's product narrative. The appeal of Gemma 4 is not just that "Google also released an open model." It is that Gemma 4 is trying to cover a wide range of lighter and mid-weight tasks that previously pushed teams toward cloud APIs.
3. People Are Still Cautious About the Gap Between Early Hands-On Results and Leaderboard Scores
Some developers shared day-one testing results and felt that Gemma 4 was still less stable than other models in certain coding tasks. Others noted that, on launch day, tooling support, chat templates, and tool-calling integrations are often still being fixed quickly, so it is too early to draw hard conclusions.
That discussion is valuable because it reminds us to separate two things:
- The model's potential
- Whether the surrounding tool ecosystem has caught up
An official capability claim can be strong, but that does not mean you will get the same experience today in llama.cpp, Ollama, a given quantized build, or a third-party frontend.
4. The Community Still Wants to See Real Comparisons on Private Tasks
Another practical argument on Hacker News was that if you really care whether a model fits your use case, public leaderboards are not enough. You need to test it against your own task set.
This is especially true for:
- Internal knowledge-base Q&A
- OCR and layout parsing
- Code rewriting and refactoring
- Structured information extraction
- Multilingual support or translation
Which Teams Should Prioritize Gemma 4?
If your team or product falls into one of the following categories, Gemma 4 deserves to enter your evaluation list soon.
1. Teams Building Local-First AI Products
Examples include desktop assistants, mobile AI features, private knowledge assistants, and document-understanding tools. Gemma 4 offers a relatively natural product path from edge-sized variants up to larger local models.
2. Teams That Are Sensitive to Licensing and Data Control
Apache 2.0 is a meaningful advantage for many companies, especially those that do not want to re-evaluate model license risk later in the commercialization process.
3. Developers Who Need Multimodal Capability but Do Not Want to Bet Entirely on Closed APIs
Gemma 4 is not a universal answer that is best at everything. But combining image, video, audio, long context, and tool use under a single open-model line is already compelling on its own.
But Do Not Overestimate Gemma 4 Yet
An introductory article that only lists strengths is not very useful. At this stage, Gemma 4 is better understood as a new option worth serious evaluation, not as the default best choice for every scenario.
At minimum, teams should keep these practical issues in mind:
- Third-party inference stack support may still be unstable at launch.
- Quantized builds can behave differently from the original models.
- Combining multimodal input, long context, and tool use still raises the engineering bar.
- A more open license does not make deployment, auditing, and security problems disappear.
In other words, Gemma 4 matters because it makes more product ideas that previously depended on closed models start to look achievable with an open stack. But whether those ideas become good products still depends on evaluation method, engineering execution, and the specific workload.
Closing Thoughts
Gemma 4 is one of the most noteworthy releases in Google's open-model strategy over the past two years. What matters most is not only its benchmark performance, and not only the fact that it comes from Google. It is the way Gemma 4 brings together several advantages that were often scattered across different model families:
- A clearer Apache 2.0 license
- A stronger agentic-workflow narrative
- More complete multimodal and long-context capability
- A more explicit local-first deployment path
For individual developers, that means Gemma 4 deserves a more serious place in local experimentation stacks. For engineering leaders, it means the next step should be running real-task evaluations soon instead of making decisions from leaderboard screenshots alone.
Gemma 4 may not be the endpoint of the open-model race, but it is very likely to become one of the defining discussion points for local AI and open models in 2026.
References
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/google-gemma-4-open-models-guide