From GLM-5.1 to Qwen3.6: Why China’s Open Model Pace Is Slowing
Using GLM-5.1, MiniMax M2.7, and Qwen3.6-Plus as case studies, this article looks at why Chinese model makers are increasingly shipping APIs first and open weights later.

Updated: April 12, 2026
Over the past year, one of the clearest patterns in the Chinese AI scene was simple: a blog post would go live, and the weights would often show up right after. Qwen, DeepSeek, Kimi, GLM, and StepFun kept resetting expectations, and a lot of developers started to assume that Chinese model vendors would keep being the main force behind flagship open-weight releases.
But by spring 2026, that rhythm had started to change.
Put GLM-5.1, MiniMax M2.7, and Qwen3.6-Plus side by side, and the pattern becomes hard to miss. All three are aimed at agentic coding, long-horizon tasks, and real workflow performance. All three also show that Chinese vendors are still highly competitive at the frontier. But at the same time, they point to something else: the launch date of a flagship model is no longer lining up as neatly with the release date of open weights.
More and more, the new pattern looks like this:
- Launch the API, coding plan, or hosted service first.
- Watch how the model behaves in real workloads, including stability, pricing, and business demand.
- Decide later whether to release weights, which model sizes to release, and how restrictive the license should be.
That does not mean Chinese companies have stopped opening models. But it does mean that open release is shifting from a default same-day move into a more cautious, staged product decision.
If you want the wider industry context first, our earlier piece on China’s LLM landscape is a good starting point. And if you want a broader open-model comparison from outside China, our Gemma 4 open models guide helps frame a very different strategy.
1. GLM-5.1: The closest thing to a classic open-model win
Out of these three examples, GLM-5.1 feels the closest to the kind of open-model story developers had gotten used to.
The GLM-5.1 model card on Hugging Face is marked with an MIT license and describes it as a next-generation flagship built for agentic engineering. What matters in that framing is not just stronger first-pass answers. The model card emphasizes something more practical: the model is supposed to keep breaking down problems, using tools, reading results, revising plans, and staying useful over hundreds of steps in long-horizon agent tasks.
That framing matters because it is very different from the 2025 race of “who sounds more human” or “who looks better in a single-round reasoning demo.” GLM-5.1 is selling a different promise: if you drop the model into a real engineering workflow, can it stay effective for a long time instead of falling apart after a few rounds?
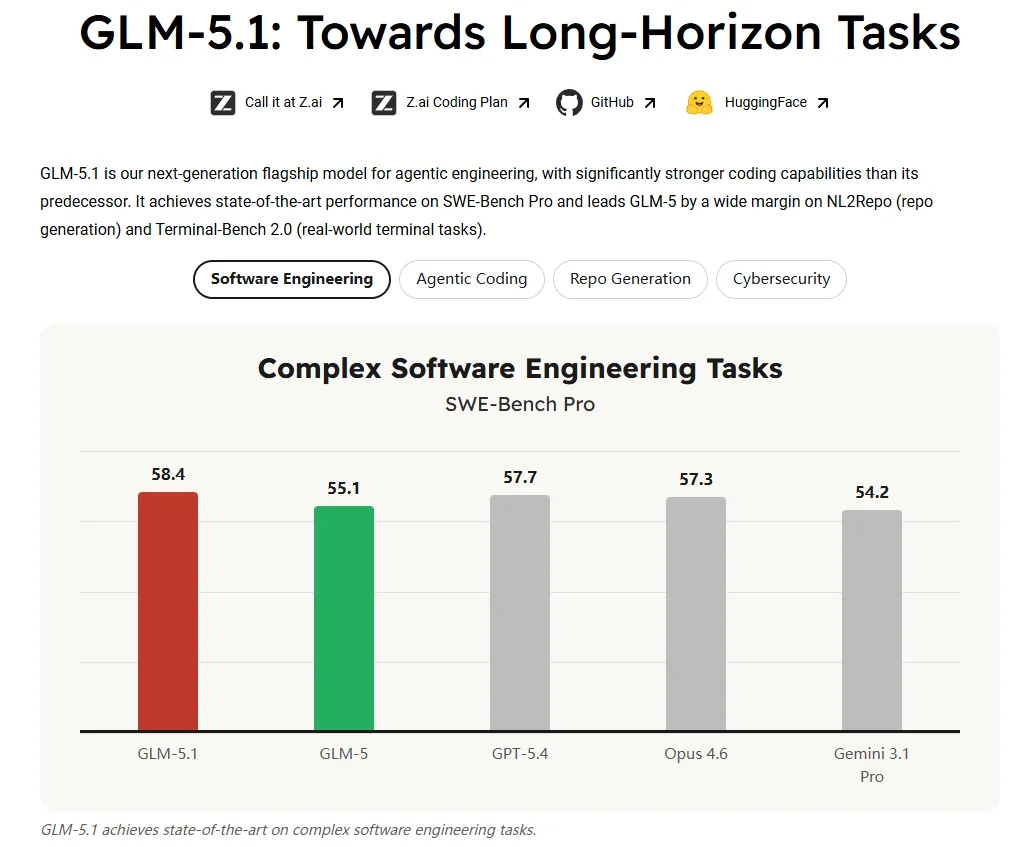
The public benchmarks that Z.ai chose to highlight fit that story. On Hugging Face, the model card lists scores such as SWE-Bench Pro 58.4, NL2Repo 42.7, and Terminal-Bench 2.0 63.5, while placing Qwen3.6-Plus, MiniMax M2.7, Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 right next to it as reference points. That alone says a lot. Z.ai is not trying to pitch GLM-5.1 as a cheaper fallback. It is trying to say that it belongs in the same top-tier agent and coding conversation.
Community discussion has mostly followed that same line.
- In one r/LocalLLaMA thread, testers argued that
GLM-5.1was already getting close to Opus 4.6 on OpenClaw-style agent benchmarks. - In another thread focused on local deployment, people were less interested in one-shot benchmark numbers and more interested in how stable the model felt across long chains of tool calls. That tells you where the community’s attention has moved: toward real agent harness behavior rather than headline scores.Source
- There has also been pushback. In Hugging Face discussions, some users have reported performance drop-offs past
100Ktokens, while others questioned how consistently some of the long-context or browsing-style benchmark claims can be reproduced.Source 1 Source 2
So the signal from GLM-5.1 is not that open models have magically caught up with closed models at zero cost. It is something more grounded: in agentic coding, open-weight models are now genuinely in the front pack, but they are still huge, still expensive to run well, and still open to debate on long-context stability.
That is why I see GLM-5.1 as the baseline case in this story. It shows that Chinese vendors have not abandoned flagship openness. But even in the most open-leaning case, the story has already shifted from “everyone can run this at home” to “developers can get the weights and build around them, but high-quality use still comes with a real barrier to entry.”
2. MiniMax M2.7: Strong performance, but the license changed the conversation fast
If GLM-5.1 represents “we still believe flagship open weights matter strategically,” then MiniMax M2.7 points to a more guarded path: release the weights, but hold tighter control over the commercial layer.

In its March 18, 2026 official post, MiniMax describes M2.7 as the first model to “deeply participate in its own evolution.” The company pushes that framing hard. This is not supposed to be just a model that writes code. It is supposed to build complex agent harnesses, maintain memory, use sophisticated skills, take part in reinforcement-learning experiments, and even help improve the next round of training and evaluation.
The benchmark numbers in the post also lean toward real workflow performance rather than generic chat quality:
SWE-Pro 56.22%VIBE-Pro 55.6%Terminal Bench 2 57.0%GDPval-AA ELO 1495- An average medal rate of
66.6%across three 24-hour autonomous runs onMLE Bench Lite
Taken together, those metrics support one core message: MiniMax wants M2.7 to be seen as a self-improving work agent, not just a somewhat stronger text model.
That pitch landed, at least at first.
- In the main r/LocalLLaMA announcement thread, many people were less interested in any single benchmark and more interested in the workflow story itself, especially the idea that the model was participating in its own iteration and evaluation loop.
- Some third-party testers also gave it a positive read in PinchBench / Kilo Bench testing, arguing that
M2.7behaves more like an agent model tuned for hard tasks than like a chatbot optimized to look fast on the surface.
But the conversation around MiniMax M2.7 quickly shifted from “this looks strong” to “does this really count as open source?”
As of April 12, 2026, the MiniMax-M2.7 repository on Hugging Face is live, but the license shown there is not a standard MIT or Apache-2.0. It is labeled modified-mit. And if you open the actual LICENSE file, the restriction becomes clear: non-commercial use is broadly allowed in an MIT-like way, but commercial use requires prior written authorization.
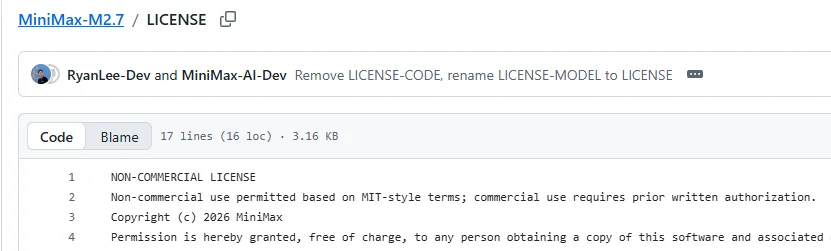
That changes the meaning of the release pretty quickly.
Because for many developers, the real question is not just “can I download the weights?” It is:
- Can I plug this into my product?
- Can I fine-tune, host, or deploy it in a commercial setting?
- Can I safely build a long-term stack on top of it?
That is exactly why Hugging Face discussions quickly filled with license questions. In the thread titled “No commercial use allowed in License?”, the core confusion is straightforward: if commercial use is tightly restricted, then this starts to look more like a downloadable evaluation release than the kind of open model developers usually mean.
That is what makes M2.7 such an important example. It is open in one sense, but it also shows a different trend very clearly: vendors may still release weights, while no longer being willing to hand over the most commercially valuable parts of the stack as freely as they did before.
3. Qwen3.6-Plus: The clearest API-first, open-later example
If you want the most obvious case of a slowing open-release cadence, Qwen3.6-Plus is probably it right now.
In its April 1, 2026 official blog post, Alibaba positions Qwen3.6-Plus as a new flagship for real-world agents and highlights a few very clear selling points:
- A default
1M context window - Significantly stronger
agentic coding - Better multimodal perception and reasoning
- Immediate availability through the API
Near the end of the post, there is one line that matters a lot: “In the coming days, we will also open-source smaller-scale variants.” That line does not reject openness. But it does make the new launch order explicit: hosted flagship first, smaller open variants later.
And that change alone was enough to shift the mood.
For a long time, Qwen had built a reputation as one of the most reliable open-model brands from China in the eyes of global developers. The expectation was not just that Qwen would keep improving. It was that strong versions would show up as open weights relatively quickly, just like before. Once that expectation gets broken, even temporarily, the community immediately starts reading it as a strategic signal.
The discussion reflects that shift pretty clearly.
- In the LocalLLaMA thread on Qwen3.6-Plus, some users openly say the model feels stronger in real coding workflows, especially when it has to recover from a failed plan and change direction.
- But in the same thread, a lot of comments stop talking about raw performance and start asking a different set of questions: why is this not open-weight on day one, when are the smaller variants coming, and is Qwen moving from open-model leader to API-first commercial product?
- Another thread, Is Qwen 3.6 going to be open weights?, shows just how central that question has already become.
More importantly, as of April 12, 2026, I still had not found an official Qwen3.6 or Qwen3.6-Plus weights repository under Qwen’s official Hugging Face organization. I want to phrase that carefully: this does not mean Alibaba has explicitly said the model will not be opened, but based on publicly verifiable information, the community was still waiting between the April 1 announcement and April 12.
That is why Qwen3.6-Plus matters as more than just another strong release. It is a real dividing-line example showing that at the flagship tier, Qwen is also starting to prioritize product rollout over immediate weight release.
4. Why is this happening? I keep coming back to four reasons
To be clear, this section is not based on a single official explanation from the companies themselves. It is my reading of the pattern across release timing, licensing choices, and community reaction.
1. The real value of agent models increasingly lives in workflows, not just raw weights
In 2024, a lot of models were still competing on single-turn answers. By 2026, the real questions look more like this:
- Can it keep working in the terminal for hours?
- Can it use tools reliably?
- Can it maintain memory?
- Can it keep converging on repo-level tasks?
Once the competition shifts toward those capabilities, the model’s value no longer sits only in the weights. It also sits in:
- scaffolds
- harnesses
- prompt engineering
- skills and MCP ecosystems
- rate limiting, caching, and cost control in production
That naturally pushes vendors toward APIs and hosted workbenches first, because those are the most complete, controllable, and monetizable forms of the product.
2. Flagship models are expensive enough that hosted rollout is the practical way to recover costs
Whether we are talking about something like GLM-5.1 in the 700B+ class or a huge MoE like MiniMax M2.7, serious high-quality usage is not just “download the weights and go.” Inference hardware, long-context handling, concurrency, caching, and tool-use costs all pile up fast.
In that environment, keeping the strongest version behind an API first is not some dramatic betrayal of openness. It is a pretty straightforward business reality.
3. Vendors seem to be moving toward tiered openness instead of all-or-nothing openness
MiniMax M2.7 is a good example of this. It is not fully closed, but it is also far from fully open. The message is basically:
- you can download the weights
- you can experiment for non-commercial purposes
- commercial deployment still needs extra permission
That suggests many vendors are trying to hold onto the distribution benefits of openness without giving up commercial control all at once.
4. The community’s definition of “open source” is now stricter than the vendors’ marketing language
There was a time when many companies could call a model open source as long as the weights were downloadable. Developers are much less willing to accept that now. The follow-up questions come immediately:
- Is this open source in the OSI sense?
- Is commercial use restricted?
- Are fine-tuning, distillation, hosting, or redistribution restricted?
- Will the license create downstream compliance problems?
So a lot of today’s friction is not really about whether a company has opened anything at all. It is about how open it needs to be before developers will trust it as infrastructure.
5. What this means for developers
If you are a developer, a team lead, or just someone who follows open models closely, this shift points to at least three practical takeaways.
First, do not assume “official blog post date = weights release date” anymore. Those two events are increasingly likely to split apart, and the gap may stretch from days into weeks or longer.
Second, treat the license as a first-class part of model evaluation. Downloadable weights do not automatically mean safe commercial use. A label like modified-mit may sound familiar, but the real restrictions can be much tighter than people assume.
Third, the key question is no longer just whether a model is open, but whether it is still giving the developer ecosystem something durable to build on. For many teams, the real need is not access to the absolute strongest version on earth. It is access to something that is commercially usable, fine-tunable, deployable, and maintainable over time.
Seen through that lens, the difference between GLM-5.1, MiniMax M2.7, and Qwen3.6-Plus is not only about technical performance. It is also about how each one positions itself toward the developer ecosystem:
GLM-5.1looks like “we are still willing to open a flagship as much as we can.”MiniMax M2.7looks like “the weights are open, but the commercial boundary is tighter.”Qwen3.6-Pluslooks like “the flagship comes to the API first, and openness now follows the product rollout instead of leading it.”
FAQ
Have Chinese model vendors stopped opening models?
No. The more accurate way to put it is this: frontier flagship releases are becoming decoupled from open-weight release timing. Some models are still opening, some are opening later, and some are opening under much tighter commercial terms.
Does this mean Qwen3.6-Plus will never be opened?
That would be too strong a conclusion. In its April 1, 2026 blog post, Qwen explicitly said smaller variants would be open-sourced in the coming days. The safer formulation is: as of April 12, 2026, no publicly verifiable official weights repository had appeared yet, and the community was still waiting.
Does MiniMax M2.7 count as a truly open model?
That depends on your standard. If your only criterion is “can I download the weights,” then yes, it is open in that sense. But if you care about OSI-style openness, unrestricted commercial use, and downstream compatibility, then M2.7 is clearly more restrictive than something like MIT or Apache-2.0.
Closing thoughts
If you only look at model capability, Chinese vendors have not slowed down at all. If anything, GLM-5.1, MiniMax M2.7, and Qwen3.6-Plus show that the race has moved well beyond chatbots and into real agent workflows.
What has changed is not whether the models are getting better. It is that the distance between the best models and the open community is widening a little again.
I would describe this as a new staged-openness strategy rather than a simple turn toward closed models. But for developers, it is still a signal worth paying attention to. If more flagship models keep choosing API-first, license-later, and weights-when-stable, then the deep trust Chinese vendors built in the global open-model community during 2025 may not carry forward as automatically as many people assumed.
Related resources
- GLM-5.1 Hugging Face model card
- MiniMax M2.7 official blog
- MiniMax M2.7 Hugging Face page
- MiniMax M2.7 LICENSE
- Qwen3.6-Plus official blog
- LocalLLaMA: Qwen3.6-Plus
- LocalLLaMA: Is Qwen 3.6 going to be open weights?
- LocalLLaMA: MiniMax-M2.7 Announced!
- LocalLLaMA: Benchmarked MiniMax M2.7
- LocalLLaMA: GLM 5.1
- LocalLLaMA: GLM 5.1 crushes every other model except Opus in agentic benchmark
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/glm-5-1-minimax-m2-7-open-model-shift