DeepSeek V4 Preview Goes Live: 1M Context, Flash/Pro Models, and Latest API Pricing
As of April 24, 2026, DeepSeek has publicly rolled out the DeepSeek V4 series across its API docs and Hugging Face. This article breaks down the Flash and Pro models, the 1M-token context window, thinking mode, API pricing, and open weights.

As of April 24, 2026, DeepSeek has publicly rolled out the DeepSeek V4 series across its official API documentation and Hugging Face. According to the Hugging Face model card, this generation is currently labeled a preview version. The information available so far shows two API model names, deepseek-v4-flash and deepseek-v4-pro, alongside public Flash / Pro weights for both Base and Instruct variants.
Based on the materials that are already public and directly verifiable, the main updates in DeepSeek V4 fall into four areas: a 1M-token context window, thinking mode enabled by default, a Flash/Pro two-tier lineup, and a published API pricing table. Together, these details define how the model is accessed, what it can do, and what it costs to run.
What Has Actually Been Released?
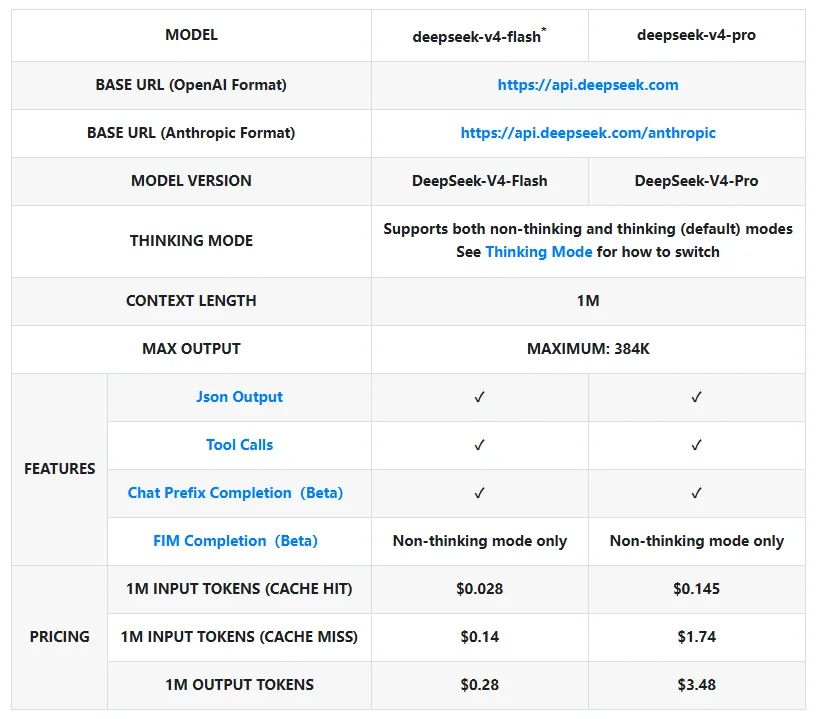
According to DeepSeek's "Models & Pricing" page, the V4 API models currently listed are:
deepseek-v4-flashdeepseek-v4-pro
The documentation shows that both models support OpenAI-compatible and Anthropic-compatible API formats. Both support thinking mode, which is enabled by default. Both also list a 1M-token context window and a 384K-token maximum output. In addition, JSON Output, Tool Calls, and prefix continuation (Beta) are available on V4, while FIM Completion (Beta) is only available when thinking mode is disabled.
This indicates that DeepSeek V4 is no longer just a research label. It has already become a production API that developers can call directly.
Thinking Mode Is On by Default, and Older Model Names Are Being Phased Out
DeepSeek's Thinking Mode documentation is also fairly explicit. V4 exposes two main controls:
thinking.enabled / disabledto switch thinking mode on or offreasoning_effortto control reasoning intensity, with the public docs listinghighandmax
The documentation states that thinking mode is enabled by default. Standard requests default to high, while some complex agent requests may be automatically escalated to max. For compatibility, low and medium are mapped to high, while xhigh is mapped to max.
Another notable change is the compatibility naming. DeepSeek notes on the pricing page that deepseek-chat and deepseek-reasoner will eventually be deprecated. For compatibility, they currently map to the non-thinking and thinking modes of deepseek-v4-flash, respectively. Teams that still rely on the older model names should pay close attention to this transition.
Four Public Repositories Are Already Live on Hugging Face
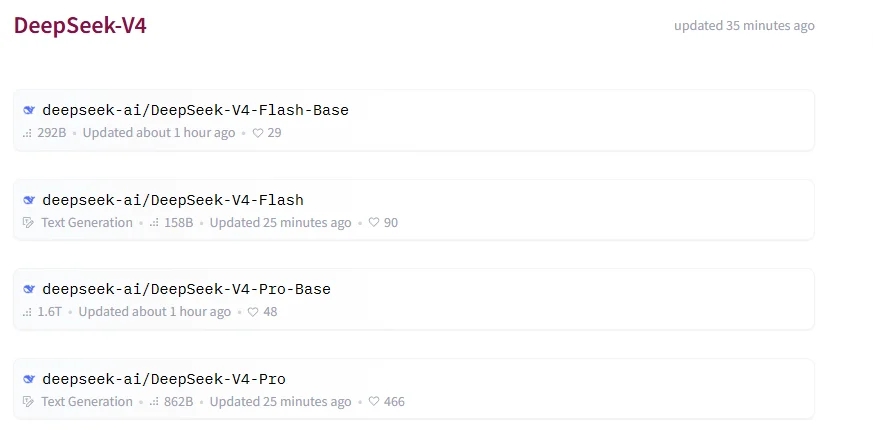
At the time of writing, DeepSeek's DeepSeek-V4 collection on Hugging Face already includes four repositories:
DeepSeek-V4-Flash-BaseDeepSeek-V4-FlashDeepSeek-V4-Pro-BaseDeepSeek-V4-Pro
The official DeepSeek-V4-Pro model card lists the following specifications:
| Model | Total Params | Activated Params | Context Length | Precision |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
The model card describes V4 as a pair of Mixture-of-Experts (MoE) language models and notes that both Pro and Flash support million-token context lengths. For teams interested in self-hosting or local deployment, that matters because V4 is not limited to an API-only release. The weights themselves are already public.
The model card also states that these repositories and weights are released under the MIT License. DeepSeek further provides encoding and inference directories to document message formatting, weight conversion, and local execution.
API Pricing Is Public, and the Gap Between Flash and Pro Is Clear
The current pricing page shows a straightforward tier split for DeepSeek V4:
| Model | Input (Cache Hit) | Input (Cache Miss) | Output |
|---|---|---|---|
| deepseek-v4-flash | CNY 0.2 / 1M tokens | CNY 1 / 1M tokens | CNY 2 / 1M tokens |
| deepseek-v4-pro | CNY 1 / 1M tokens | CNY 12 / 1M tokens | CNY 24 / 1M tokens |
This pricing makes the product split clear: Flash is aimed at cost efficiency and high-volume usage, while Pro is the higher-priced premium tier. If the workload is centered on bulk generation, lightweight Q&A, or structured extraction, Flash offers a much lower cost threshold. If the priority is harder reasoning, better long-context quality, or more demanding agent tasks, Pro's pricing provides a clearer benchmark for the high-performance tier.
What Else Does the Official Model Card Reveal?
The Hugging Face model card also includes several technical details that can be verified directly:
- DeepSeek V4 uses a hybrid attention design that combines
CSAandHCA - According to DeepSeek, compared with DeepSeek-V3.2, V4-Pro reduces per-token inference FLOPs to 27% and KV cache usage to 10% under a 1M-context setting
- The model introduces
mHC(Manifold-Constrained Hyper-Connections) - Training uses the
Muonoptimizer - Pretraining data exceeds 32T tokens
These points come from DeepSeek's own model card and linked technical report materials. Still, based on what has been published, this release is not just a version bump. It also comes with a new architecture and training story.
What Do the Evaluation Results Actually Show?
The DeepSeek-V4-Pro model card also publishes a full set of base-model evaluations comparing DeepSeek-V3.2-Base, DeepSeek-V4-Flash-Base, and DeepSeek-V4-Pro-Base. Across that table, the clearest takeaway is that V4-Pro-Base shows a noticeable lift in knowledge-heavy tasks, long-context benchmarks, and several harder factual QA tasks.
Here are some of the most representative results:
| Benchmark | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|
| MMLU-Pro (EM) | 65.5 | 68.3 | 73.5 |
| MultiLoKo (EM) | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 28.3 | 30.1 | 55.2 |
| FACTS Parametric (EM) | 27.1 | 33.9 | 62.6 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| LongBench-V2 (EM) | 40.2 | 44.7 | 51.5 |
This table points to three fairly direct trends.
First, V4-Pro-Base is materially stronger than the previous generation on knowledge-oriented tasks. On benchmarks such as Simple-QA verified and FACTS Parametric, which lean more heavily toward factual and parametric knowledge, the jump over V3.2-Base is substantial. At minimum, that suggests DeepSeek's claims of stronger knowledge performance do show up in its public benchmark table.
Second, the long-context improvement looks systematic rather than isolated. LongBench-V2 rises from 40.2 to 51.5, and when read alongside the model card's efficiency claims around 1M context, it becomes clear that long-context performance is one of the central themes of this release.
Third, the product split between Flash and Pro is also visible in the results. Flash-Base is not simply a stripped-down budget model. It already beats V3.2-Base on multiple knowledge and coding tasks. But Pro-Base remains the higher-ceiling flagship, especially on knowledge QA, harder exam-style tasks, and long-context benchmarks.
That said, one caveat matters: these Evaluation Results are official comparisons between base models, not a guarantee of final real-world product behavior. In V4, thinking mode and reasoning-effort controls sit directly in the API layer, so actual usage quality can still vary with inference budget and configuration.
What Does "DeepSeek-V4-Pro-Max vs Frontier Models" Tell Us?
The model card also includes the more closely watched comparison table titled DeepSeek-V4-Pro-Max vs Frontier Models. Here, DS-V4-Pro Max is compared with several closed frontier models, including Opus-4.6 Max, GPT-5.4 xHigh, Gemini-3.1-Pro High, K2.6 Thinking, and GLM-5.1 Thinking.
Some of the most representative rows are as follows:
| Benchmark | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 84.4 |
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | 3206 |
| MRCR 1M (MMR) | 92.9 | - | 76.3 | 83.5 |
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.6 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 51.8 |
If this table had to be reduced to one line, it would be this: DeepSeek-V4-Pro-Max is already highly competitive in code and several tool-using or agent-style tasks, and even beats leading closed models on some rows, but it has not established across-the-board leadership on the hardest general-knowledge and extreme-reasoning benchmarks.
That comparison highlights four broader points.
First, DeepSeek clearly wants to position this model in the first tier of open models. The model card explicitly describes DeepSeek-V4-Pro-Max as "the best open-source model" at present. Looking at the scores, that positioning is not without support, especially on code- and tool-oriented benchmarks such as LiveCodeBench, Codeforces, and MCPAtlas Public.
Second, it is not matching frontier closed models on every axis. On benchmarks such as MMLU-Pro, GPQA Diamond, HLE, and Apex, which lean more toward broad knowledge, research-heavy reasoning, or very high-difficulty problems, models like Gemini-3.1-Pro High and GPT-5.4 xHigh still maintain a stronger upper bound. In other words, V4-Pro-Max looks more like a model that has narrowed the gap sharply, rather than one that has overtaken closed leaders everywhere.
Third, coding and engineering workflows may be where the model stands out most right now. LiveCodeBench at 93.5, Codeforces at 3206, plus SWE Verified at 80.6 and Terminal Bench 2.0 at 67.9 together suggest that DeepSeek is not only optimizing for exam-style benchmarks. It is also emphasizing coding, terminal tasks, and agentic workflow performance.
Fourth, long-context capability and Chinese-language knowledge look like important differentiators. A score of 84.4 on Chinese-SimpleQA is already very high, while results such as MRCR 1M and CorpusQA 1M suggest that the million-token context window is not just a specification-sheet headline. For teams working on long-document handling, Chinese QA, or local knowledge workflows, those details may matter more than generic benchmark rankings.
Even here, though, an important caveat remains: this is still an official model-card comparison, and evaluation settings, reasoning budgets, and tool configurations are not necessarily identical across vendors. A more grounded interpretation is not "DeepSeek has already won across the board," but rather that DeepSeek has narrowed the gap between open models and frontier closed models to a point where many teams will take it seriously in evaluation.
What Can Be Stated with Confidence So Far?
Based on the official materials that are already public, at least a few points are already clear:
- DeepSeek V4 is already in a usable state, since the API docs, pricing page, and Hugging Face repositories are all live.
- This generation clearly has at least two tiers, Flash and Pro, and both API access and public weights are part of the release.
- A 1M context window and thinking mode are core traits of V4, not optional add-ons for just one model.
- The older
deepseek-chatanddeepseek-reasonernaming scheme is on its way out, with the migration path already pointing toward V4.
For anyone tracking the pace of Chinese model releases, the significance of this launch is straightforward: DeepSeek has moved V4 beyond a next-generation codename into a stage where documentation, API access, pricing, and weights are all public at the same time. From here, the next questions are likely to center on real-world quality, third-party deployment support, and what developers report in actual workflows.
Related Resources
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/deepseek-v4-release-api-pricing-open-weights



