Claude Opus 4.7 Backlash Explained: Why Did Reactions Split So Sharply?
Claude Opus 4.7 launched on April 16, 2026. This article draws on Anthropic's official notes plus Reddit and Hacker News discussions to unpack its upgrades, criticism, and why reactions split so quickly.

On April 16, 2026, Anthropic released Claude Opus 4.7. The company's positioning was unusually clear: this was its "most powerful generally available model" yet, with a major push around complex reasoning, long-horizon agentic work, knowledge-heavy tasks, visual understanding, and memory. Anthropic also updated Claude Code, API parameters, and migration docs at the same time, which made it clear that Opus 4.7 was meant to become the new default high-end model.
The first wave of community feedback, however, was anything but calm. Among heavy Claude Code users, API users, and developers on Hacker News, Opus 4.7 quickly drew sharply split reactions. Some saw it as a real upgrade. Others argued that it had become "more confidently wrong," burned through more tokens, demanded more tuning, and in practical workflows could feel harder to use than 4.6.
This article is based on Anthropic's official release notes, Claude API documentation, and public Reddit and Hacker News discussions available as of April 18, 2026. Community reactions are not benchmark tests in the strict sense, but they are often the fastest way to understand how a model feels inside real workflows.
For broader context, see Why the community erupted after Anthropic called out "distillation attacks". If you want a parallel example from another vendor's coding-model launch, compare it with GPT-5.3-Codex release analysis: upgrades, benchmark results, and rollout advice.
The core takeaway is this: Claude Opus 4.7 looks less like a simple win or failure, and more like an upgrade with a higher ceiling and a higher migration cost. Anthropic and some power users are focusing on gains in long tasks, complex engineering work, and vision-heavy inputs. Other users are feeling stronger literalness, higher token usage, and the kind of "confident mistakes" that become especially painful once they show up in real work.
That is also the central point of this article: the split reaction is not happening because people are evaluating different models. It is happening because they are using the same model for different kinds of work, with very different tolerance for changes in default behavior.
What actually changed in Claude Opus 4.7?
If you compress all of the launch material into the few changes that most affect real usage, the story mainly comes down to three groups.
The first is capability positioning. Anthropic is explicitly pushing Opus 4.7 toward long-horizon agentic work: multi-step tasks, maintaining goals over long contexts, and continuing to make progress when tools fail. That is why both the official examples and partner quotes focus so heavily on "completing the job" rather than simply sounding better in conversation.
The second is input scope. The API docs describe Opus 4.7 as the first Claude model with support for higher-resolution image input, which clearly points toward screenshot analysis, document understanding, and computer-use workflows. In other words, Anthropic is not really selling a more conversational Opus here. It is selling an Opus that fits more naturally into actual work pipelines.
The third change is the one that is easiest to underestimate: the default behavior changed. This release did not just add capabilities. It also changed the interaction contract. According to Anthropic's docs, Opus 4.7 adds xhigh effort, removes the old extended thinking budgets, keeps only adaptive thinking, hides the thinking summary by default, and uses a new tokenizer that can increase token usage for some types of text. More importantly, Anthropic explicitly says the model now follows instructions more literally, generalizes less on its own at low effort levels, and calls tools less often by default.
That means many users thought they were simply upgrading a model, when in practice they were upgrading an entire default workflow. Once that point is missed, a split reaction afterward is almost inevitable.
Why is Anthropic optimistic while some users feel it got worse?
Because Anthropic and end users are not measuring the same thing.
Anthropic's narrative is very consistent: Opus 4.7 is stronger than 4.6 for coding, long tasks, vision, memory, and knowledge work, and partners describe it as more reliable, more complete, and less prone to tool-use mistakes. Most mainstream coverage broadly accepted that framing, though not without caveats. VentureBeat's summary is a good example. It acknowledges that Opus 4.7 is impressive, but frames it less as total domination and more as Anthropic regaining a narrow lead on a specific class of high-value tasks.
At the same time, reporting from The Verge and Tom's Guide highlights something else: this launch was not only about model capability. It was also a safety-and-productization story. Opus 4.7 was positioned as something more suitable for public release than Mythos Preview, and that naturally affects tone, boundaries, and defaults. So when some users say the model feels more restrained or more cautious, that is not necessarily a hallucination on their part.
That subtle shift also shows up in firsthand developer impressions.
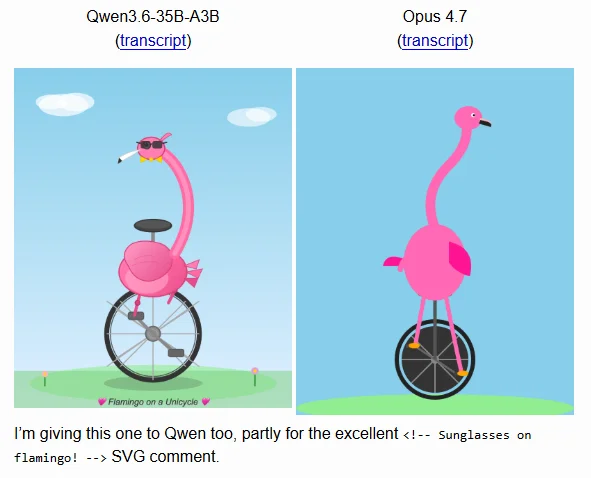 <small>Simon Willison's SVG test</small>
<small>Simon Willison's SVG test</small>
The problem is that frontline users do not start by interpreting those changes through product strategy. They feel them through their daily workflow. So while Anthropic sees "higher completion rates," users may first feel, "Why do I suddenly have to specify so much more than before?"
Where is the negative feedback actually concentrated?
If you line up Reddit threads, Hacker News comments, and media coverage, the complaints converge quite a bit. Most of them fall into four buckets.
1) The biggest trust killer is not being wrong, but being wrong with confidence
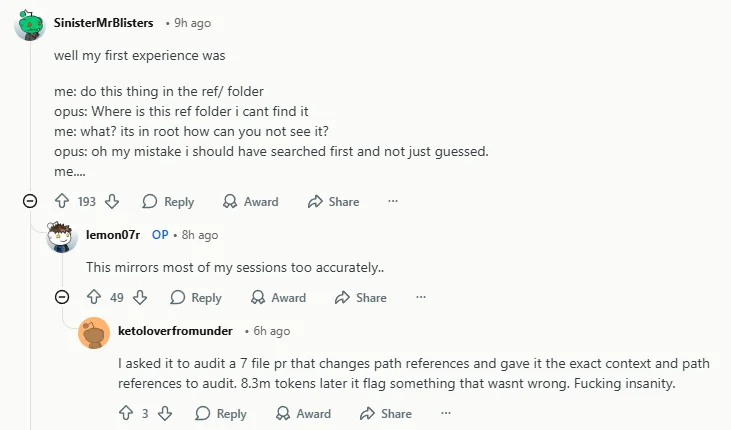
The Reddit post that spread so quickly resonated not because it merely argued that 4.7 was less intelligent. It landed because it captured something that engineering users find much harder to tolerate: the model assuming facts that were never verified, failing to check evidence first, and continuing to defend its explanation even after being corrected. Business Insider described this mood as a growing "Claude-lash," which suggests this is no longer just isolated frustration inside a niche community. It has started turning into a broader reputation problem.
For heavy coding users, ordinary mistakes are tolerable. Being highly certain before it has actually checked the facts is what really breaks trust, because it pushes review costs directly back onto the human.
2) It is more sensitive to prompt wording and more sensitive to effort settings
Another clear theme in the feedback is that 4.7 is not unusable. It is just more demanding about how you use it than 4.6 was. Reddit and Hacker News both contain two seemingly conflicting takes: one group says it is an obvious regression, while another says it becomes more stable inside Claude Code, long-context workflows, and high or xhigh effort modes. Those claims are not actually incompatible. If anything, they point straight back to the change in defaults.
Anthropic's own docs state this fairly directly: the model is more literal, less eager to generalize automatically, and better suited to higher effort settings for coding and agentic work. In other words, workflows that used to keep moving with vague instructions are now more likely to stall when the prompt is not specific enough.
3) Rising costs are easier to notice than higher capability
Once you combine the new tokenizer, adaptive thinking, and higher effort modes, the first thing many users notice is not task completion. It is token bills, response latency, and extra rework. If users do not clearly feel that "more expensive" also means "less human supervision needed," the negative impression of 4.7 can escalate quickly.
So the real issue was never just "Why are token counts higher?" It was, did those extra tokens actually buy back less oversight from the human?
4) Model issues and product issues are getting mixed together
Many Hacker News users may not be reacting only to the model itself. Their frustration often reflects the combined effect of Claude Chat, Claude Code, connectors, hosted environments, the CLI, API parameters, and subscription packaging. Once all of those layers are involved, observability and consistency both get worse. It becomes hard for users to tell whether a failure came from model quality, input method, insufficient effort, or a product-level default that changed somewhere else.
Once diagnosis gets harder, users tend to blame the model for all of the friction. That is one reason the exact same release can be described as both "stronger" and "worse."
Why did this controversy get amplified?
Beyond the model changes themselves, there are at least two background factors that intensified the reaction.
First, this dissatisfaction did not begin on the day 4.7 launched. Before release, outlets like VentureBeat, The Register, and InfoWorld were already covering complaints that Claude Code had become "dumber" or had been nerfed. In other words, Anthropic launched a new model into an environment where rollback anxiety was already present, so users were primed to read new changes more skeptically.
Second, developers expect something different from Claude than they do from a casual chat model. Core Claude Code users are not just asking questions. They use it to modify code, inspect logs, fix bugs, and push through long task chains. That makes them unusually sensitive to behaviors like whether the model checks things proactively, whether it actually reads the whole file, and whether it course-corrects quickly after a mistake. If a new release wobbles on those points, the backlash will be much stronger than it would be for a general chat product.
That is also why small tests like Simon Willison's still matter. They do not necessarily prove that 4.7 is broadly worse, but they remind us of something important: a model can improve on major benchmarks and still disappoint on the smaller tasks users notice first.
So are these negative reactions valid?
My take is: yes, they are valid, but they should not be flattened into "Opus 4.7 failed."
The valid part is straightforward. A real group of heavy users did report an immediate sense of regression after launch, especially around hallucinations, confident mistakes, unstable defaults, and rising costs. Those complaints are not isolated anecdotes. Reddit, Hacker News, Business Insider, and the earlier "nerf" discussion all reinforce that picture.
The reason it should not simply be labeled a failure is that another group of users also reported clear gains, especially in Claude Code, long-context work, long-horizon tasks, and higher-effort settings. Put differently, 4.7 seems to have raised both the model's ceiling and the bar for using it well. If you are willing to recalibrate your workflow, it may be stronger than 4.6. If you expected a seamless upgrade, it can easily feel worse.
How should you evaluate whether upgrading is worth it?
If the goal is not to chase launch-week hype, but to decide whether Opus 4.7 deserves a place in your day-to-day workflow, then a small comparative test is the minimum.
1) Do not only measure first-turn quality. Measure rework cost.
Many models look impressive in a one-shot demo. What really determines productivity is:
- whether the model checks facts proactively;
- whether it corrects itself quickly after feedback;
- whether it repeats the same category of mistake;
- how many times you have to intervene before a task is genuinely done.
That matters more than whether the first response looks clever.
2) Test default mode and high-effort mode separately
Because 4.7's behavior is clearly shaped by effort settings, it makes sense to compare at least three modes: default, high, and xhigh. Otherwise it is easy to misread a configuration issue as a full-model regression, or to mistake gains in an expensive mode for gains in every mode.
3) Track token use and latency on their own
A large share of the Opus 4.7 debate is really about cost perception. If you only measure whether tasks succeed or fail, and ignore token counts, latency, and rework, you will struggle to reach a conclusion that is actually meaningful for a team.
4) Check whether you are still relying on old 4.6 habits
If your past workflow depended on Claude "filling in the blanks" by itself, then prompt style deserves special scrutiny now. When 4.7 is more literal and more restrained, you often need to spell out instructions like "check these files first," "verify before concluding," and "do not invent missing configuration."
That absolutely raises the usage threshold, but it may simply be the practical constraint of the current release.
Conclusion
The release of Claude Opus 4.7 was not just another "bigger parameters, higher scores" update. It was a more obvious redesign aimed at agentic workflows. Anthropic's narrative is that the model is better at long tasks, more reliable, more capable with images, better at memory, and better suited to engineering-style agents.
But the community reaction after launch highlights the other side of that story: when model defaults, tokenizer behavior, thinking modes, visibility, and product configuration all change at once, users can feel more friction, less control, and less trust immediately, even if objective capability went up.
So the most accurate reading of Opus 4.7 right now may be neither "masterpiece" nor "disaster," but this: it looks like a higher-ceiling release that is also pickier about environment and method by default. If you are willing to retune your workflow, it may outperform 4.6. If you expect a seamless upgrade, it can create a very noticeable drop in comfort.
That is why these negative reactions matter. They are not just emotional venting. They are a useful signal to every model vendor that shipping frontier models cannot rely on benchmarks and partner testimonials alone. Migration cost, defaults, and user observability matter just as much.
Related resources
- Anthropic announcement: Introducing Claude Opus 4.7
- Claude API Docs: What's new in Claude Opus 4.7
- Claude API Docs: Migration guide
- Reddit: Opus 4.7 is legendarily bad. I cannot believe this.
- Hacker News: Claude Opus 4.7 (id=47793411)
- Business Insider: The Claude-lash is here: Opus 4.7 is burning through tokens and some people's patience
- VentureBeat: Anthropic releases Claude Opus 4.7, narrowly retaking lead for most powerful generally available LLM
- The Verge: Anthropic releases a new Opus model amid Mythos Preview buzz
- Tom's Guide: Anthropic just released Opus 4.7 — the 'civilian' version of the AI they said was too dangerous for us
- Simon Willison: Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
- VentureBeat: Is Anthropic 'nerfing' Claude? Users increasingly report performance degradation as leaders push back
- The Register: AMD's AI director slams Claude Code for becoming dumber and lazier since last update
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/claude-opus-4-7-feedback-analysis



