Qwen3-Coder Explained: Performance Analysis, Pricing Insights, and Getting Started Guide
An interpretation of the Qwen3-Coder release, summarizing the latest news, analyzing its performance, pricing, and usage methods to help you quickly understand this new generation open-source coding large model.

Introduction
In July this year, Alibaba’s Qwen team released Qwen3-Coder, a large model claimed to rival Claude Sonnet 4, specially designed for code generation and intelligent agent development scenarios. For programmers, fundamental concerns include whether the AI assistant can truly be put to work, the practical user experience, pricing, and whether it is convenient to use. As a developer who has personally experienced and long followed LLM evolution and open-source community trends, I am happy to discuss this highly anticipated and heavyweight new product.
1. What is Qwen3-Coder?
Let’s first clarify the product positioning. Qwen3-Coder belongs to the Qwen3 series’ code expert models (Agentic Code LLM). The current strongest version is “Qwen3-Coder-480B-A35B-Instruct,” with 48 billion parameters, structured as a MoE (Mixture-of-Experts) architecture, activating 3.5 billion main parameters during inference.
- Massive Context Capacity: Natively supports 256K tokens of context, optimized by Yarn to reach up to 1 million tokens, which is crucial for complex engineering scenarios requiring global understanding of code repositories and dependency analysis.
- Multi-language Support: Built-in support for 358 programming languages covering mainstream business development environments.
- Agent-level Task Specialization: Enhances traditional features such as code completion, bug fixing, and comment generation, and especially strengthens typical large project scenarios like “Agentic Coding,” “agent controlling browsers,” and “multi-tool orchestration” (ranking top in SWE-Bench, BFCL benchmarks).
- Code Reinforcement Learning Driven: During training, large-scale real code test cases were introduced, improving code execution success rates via Code RL and Agent RL (multi-round agent interactions), resulting in strong actual deployment performance.
2. Performance Comparison and Evaluation Highlights
Performance Compared to Competitors and Innovations
According to official evaluations and community feedback, Qwen3-Coder performs on par with the closed-source benchmark Claude Sonnet 4 in code generation and complex agent workflow scenarios, and even surpasses it in some open-source tasks (e.g., SWE-Bench Verified). Community testing (dev.to) also mentions that the Qwen3 series can challenge (and even outperform) Claude’s high-end large models on the Aider coding benchmark even in "non-thinking mode," demonstrating excellent compatibility and versatility in real projects.
Some core metrics are as follows:

Qwen3-Coder performs excellently across several Agentic benchmarks, especially in Agentic Coding. It scored 69.6 on SWE-bench Verified (with OpenHands, 500 turns), very close to Claude Sonnet-4’s 70.4 (a small gap), and surpassing the recent Kimi-K2 score of 65.4; on SWE-bench Verified (with OpenHands, 100 turns), Qwen3-Coder scored 67.0, also close to Claude Sonnet-4’s 68.0. In Agentic Browser Use, Qwen3-Coder’s WebArena score is 49.9, Mind2Web score is 55.8—slightly below Claude Sonnet-4 (51.1) on WebArena, but significantly higher than all other models on Mind2Web, including Claude Sonnet-4 (47.4) and GPT-4.1 (49.6). For Agentic Tool Use, Qwen3-Coder scored 77.5 on TAU-Bench Retail, slightly lower than Claude Sonnet-4’s 80.5 but still the best among open models.
Innovation Mechanism — Hybrid Reasoning and Thought Budget
One of Qwen3’s biggest features is the “hybrid reasoning mode”: developers can select “thinking mode” or “non-thinking mode” according to task complexity. Simple tasks use “fast thinking,” while complex problems or those requiring deep chain reasoning (CoT) automatically switch to “slow thinking.”(Please note that as of the publication of this article, qwen3-coder does not support thinking mode.)
- “Fast response” saves inference resources, facilitating streaming prompts and high-frequency completions;
- “Slow reasoning” produces results approaching human “step-by-step meticulous thinking” in multi-step computations and code logic scenarios. This can be flexibly toggled via API control parameters and in deployment scenarios like vllm/Sglang, truly enabling AI to “use intelligence where it counts,” allowing developers to finely balance cost—latency—solution quality.
Toolchain Ecosystem and Plugin Compatibility
Qwen3-Coder provides a tailored tool for AI programming agent ecosystems — Qwen Code CLI (forked from Gemini CLI), along with comprehensive adaptation to frequently used developer tools like Claude Code and Cline, significantly lowering the practical adoption threshold. You can use the official CLI or easily configure an API key and Base URL to connect to popular agent workflows such as Cline and Claude Code, offering great flexibility.
3. Pricing Model and Compute Requirements
Pricing Analysis
The main offering for Qwen3-Coder currently is API calls, without a monthly subscription for individuals (mostly token-based billing). Alibaba Cloud API or OpenRouter platform can be used; the pricing is relatively expensive within mainstream AI coding tools—medium to large projects may spend tens or hundreds of yuan quickly (V2EX community feedback) with several large tasks consuming dozens of yuan, even the free 1 million token grant can be quickly exhausted with multi-round operations costing a lot.
- The official platform occasionally offers free token quotas (~1 million tokens per ID), but usage relates to task complexity and tokens get consumed fast.
- Public cloud pricing uses tiered pricing; costs below 256K tokens are cheaper, but beyond 256K tokens it becomes more expensive than Claude 4 Sonnet.
- No monthly or package plans; token-based billing is friendlier for large-volume enterprise needs but less friendly for individual developers.
Limited-time discount is active.
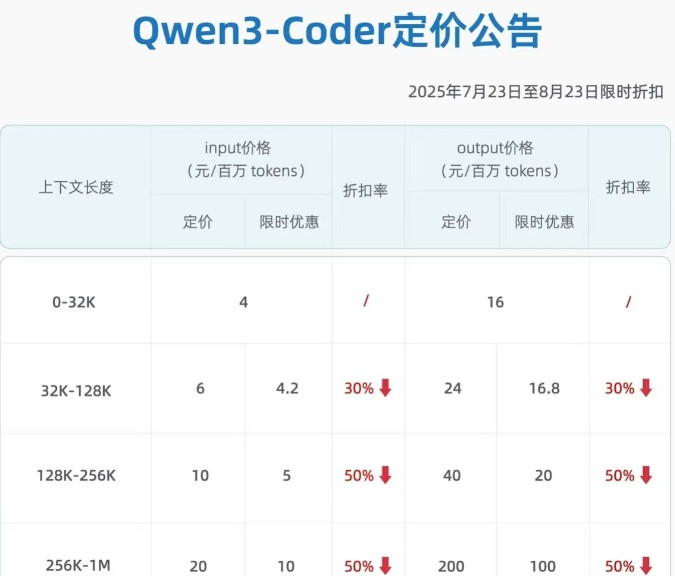
Limited-time discount from July 23 to August 23, 2025
| Context Length | Input Price (CNY/million tokens) Standard | Input Price (CNY/million tokens) Discounted | Discount Rate | Output Price (CNY/million tokens) Standard | Output Price (CNY/million tokens) Discounted | Discount Rate |
|---|---|---|---|---|---|---|
| 0-32K | 4 | / | / | 16 | / | / |
| 32K-128K | 6 | 4.2 | 30% ↓ | 24 | 16.8 | 30% ↓ |
| 128K-256K | 10 | 5 | 50% ↓ | 40 | 20 | 50% ↓ |
| 256K-1M | 20 | 10 | 50% ↓ | 200 | 100 | 50% ↓ |
Furthermore, the official Lingma plugin (currently free for individual users) already offers qwen3-coder. Also, the ModelScope community's inference service provides 2000 free requests daily (https://modelscope.cn/models/Qwen/Qwen3-Coder-480B-A35B-Instruct).
Deployment and Hardware Costs
- Because it is based on MoE plus dynamic quantization and other new technologies, the full 480B parameter model requires about 270GB VRAM at 4-bit precision (professional GPUs/high-performance local compute), with local deployment recommended on smaller models—currently mainly suited for cloud APIs or high-compute servers.
- Community members have attempted local quantized inference on high-end setups like M3 Ultra 512GB or dual RTX 3090 cards. Local quantized inference is possible but has a high entry barrier for ordinary personal users.
- Smaller parameter models (e.g., upcoming 32B/30B) are expected to be released later, more suitable for daily personal development and local IDE integration.
4. How to Actually Use Qwen3-Coder
1. Official API Calls (Alibaba Cloud Model Studio)
- Register an Alibaba Cloud account, go to the Model Studio Console, and apply for a Qwen3-Coder API Key.
- Select model version (e.g., 480B-A35B-Instruct) to get API access.
- When coding, call the API with the standard OpenAI SDK, set base_url to
https://dashscope-intl.aliyuncs.com/compatible-mode/v1, model parameter toqwen3-coder-plus, and configure the DASHSCOPE_API_KEY environment variable.
Example code:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
prompt = "Help me write a web page for an online bookstore"
completion = client.chat.completions.create(
model="qwen3-coder-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
)
print(completion.choices[0].message.content.strip())
2. Qwen Code & Claude Code Toolchains
- Qwen Code CLI (install via
npm i -g @qwen-code/qwen-code), suitable for developers who like terminal interactions, project analysis, and bulk multi-project code operations. - You can set Qwen3-Coder as the backend for Claude Code (via API-compatible proxy), simply set BaseUrl to Alibaba Cloud’s address and token to your API key to seamlessly switch models in the same code assistant console.
- There is support for open-source local frameworks like Cline, ollama, with anticipated future support for personal local or multi-machine parallel deployments.
3. Other Community AI Coding Plugins like Cline
Similar to above, just choose OpenAI-compatible mode and adjust base and apiKey.
Cline version 3.20.0 already supports Qwen as a model provider.
4. Community Ecosystem
- Model weights have been uploaded to HuggingFace and ModelScope. Developers can customize second-stage development or start small localized deployments.
5. Experience, Suitable Scenarios, and Shortcomings
Experience and Discussion
- Positive Experience: The large model performs excellently on complex requirement code and long-chain code projects, with strong collaboration, orchestration, and external tool calling abilities. Often used in team code reviews, automated refactoring, and large-scale code generation.
- Feedback and Issues: 1) Price is relatively high, free quota experience limited; individual users should be cautious with large tasks to avoid overspending; 2) In consumer scenarios, code aesthetics and front-end design still lag behind Claude/Gemini, mainly targeting backend engineering and automated tooling development; 3) Compatibility with some third-party IDEs and plugins is still pending follow-up.
As of this article’s release, many users report bugs in tool calling that repeatedly invoke file-read tools causing rapid token consumption.
https://github.com/QwenLM/qwen-code/issues/66
Though this issue was mentioned in qwen-code (CLI coding tool), other users employing plugins + API have encountered similar problems.
Best Fit Scenarios
- Medium to large projects, Agent development, automated toolchains, DevOps, CI/CD scenarios
- Complex engineering requiring long-context memory, repo-level code refactoring, and static analysis
Future Outlook
It is expected that smaller versions of Qwen3-Coder will continue to be released, supporting a wider developer ecosystem and lowering the local deployment barrier. Coupled with Alibaba Cloud’s ecosystem improving advanced programming agents and automated compilation environments, “letting AI write code” will truly move from “usable” to “user-friendly.”
Conclusion
Qwen3-Coder is undoubtedly one of the most noteworthy innovative products in AI coding for 2025. It is not only an evolution in single-point code generation capability but also achieves breakthroughs matching global commercial leading products in supporting long-chain agents and multi-round agent interaction deployment. Although it is “not cheap to use” and has a high local deployment barrier, the approach it leads — enabling code assistants to “intelligently take up jobs” — is already changing development paradigms. For teams and large projects, it is a worthwhile new choice to invest in and try.
FAQ
Q1: Can Qwen3-Coder be used for free?
Currently, platforms like Alibaba Cloud Model Studio provide new users with a free quota of 1 million tokens, but consumption is fast. Large projects or multiple calls require own funding.
Q2: Does Qwen3-Coder support local deployment? Is the barrier high?
The 480B-A35B model mainly targets high-compute servers (professional GPUs); local quantized deployment requires 512GB RAM and top-tier GPUs. Smaller models planned for future release can be tried on mainstream GPUs for small projects.
Q3: How does it compare to Claude Code, Gemini, etc.?
In code capability, long context, and multi-round agent tasks, it is on par with top models like Claude Sonnet 4 and Gemini 2.5. It even surpasses them in some benchmarks, especially code generation. However, aspects like code aesthetics and front-end generation still need ongoing improvement.
Q4: What is the approximate price? How to avoid “overspending”?
API calls are generally priced by input/output tokens, somewhat higher than mainstream AI coding assistants. It is recommended to estimate token consumption carefully for large projects and trial in limited scenarios before full investment — otherwise, a big code cleanup could cost tens of yuan at once.
References
- Qwen3-Coder Official Blog, API and Code Samples
- V2EX Community Discussion and Pricing Experience for Qwen3-Coder
- Qwen3-235B-A22B Community Evaluation and Benchmark Comparison
- RunPod: Qwen3 Model Performance and Deployment Suggestions
- Digialps: Aider Coding Benchmark Community Testing and Tuning
- Hugging Face Related Model Downloads
(This article is compiled from public news, official documentation, and community user testing data. Comments and personal experience sharing are welcome.)
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/qwen3-coder-release-summary-performance-price-usage



