Zhipu AI GLM-4.5 Model Overview
This article is a compilation and introduction of the latest GLM-4.5 model released by Zhipu AI, aimed at providing developers with objective and timely technical reference.

Introduction
Recently, China has truly experienced an explosion of open-source large models. With Kimi releasing K2 and qwen launching qwen3-coder, another well-known Chinese company, Zhipu AI, has unveiled the GLM-4.5 model. In contrast, an open large model company starting with 'open' is still on its way to release theirs.
On July 28, 2025, the field of open-source foundational AI models saw an important update as Zhipu AI released its latest GLM-4.5 series models. This series aims to provide the developer community with open-source solutions that combine high performance and high efficiency through technical innovation. This article will organize and analyze the core features and performance of the GLM-4.5 series based on publicly available technical materials and evaluation data.
Main Content
1. Model Architecture and Parameters
The GLM-4.5 series includes two core models, both adopting the Mixture of Experts (MoE) architecture designed to balance model scale and computational efficiency.
| Model | Total Parameters | Activated Parameters | Key Features |
|---|---|---|---|
| GLM-4.5 | 355 billion (355B) | 32 billion (32B) | Top-tier performance, suited for high complexity reasoning and Agent tasks |
| GLM-4.5-Air | 106 billion (106B) | 12 billion (12B) | Efficient and compact (still MoE architecture), compatible with mainstream consumer hardware |
The MoE architecture activates only a subset of experts (parameters) during inference, ensuring the model maintains the strong capabilities from large parameter scale while significantly reducing actual computational load. Notably, GLM-4.5-Air’s 12B activated parameters allow it to run on consumer-grade GPUs (such as 32-64GB VRAM), and quantization techniques further lower the hardware threshold, promoting the popularization of high-performance large models among individual developers and researchers.
After China’s deepseek company released v3 and R1 models using MoE and achieved performance comparable to commercial large models, more companies have begun adopting the MoE architecture for their own models.
2. Hybrid Reasoning Mode
The GLM-4.5 series introduces an innovative "Hybrid Reasoning" framework that integrates two working modes within a single model:
- Thinking Mode: Designed for handling complex tasks, supporting multi-step reasoning, tool invocation, long-term planning, and autonomous Agent functionalities. In this mode, the model can autonomously decompose tasks and execute complex cognitive workflows.
- Non-Thinking Mode: Optimized for instant, stateless responses, suitable for dialogues, quick Q&A, and other low-latency interaction scenarios, providing extremely fast response speeds.
This dual-mode design allows the model to flexibly adapt to demands of different application scenarios, enabling developers to avoid compromise between strong reasoning capabilities and high interactivity.
3. Performance Evaluation and Benchmark Results
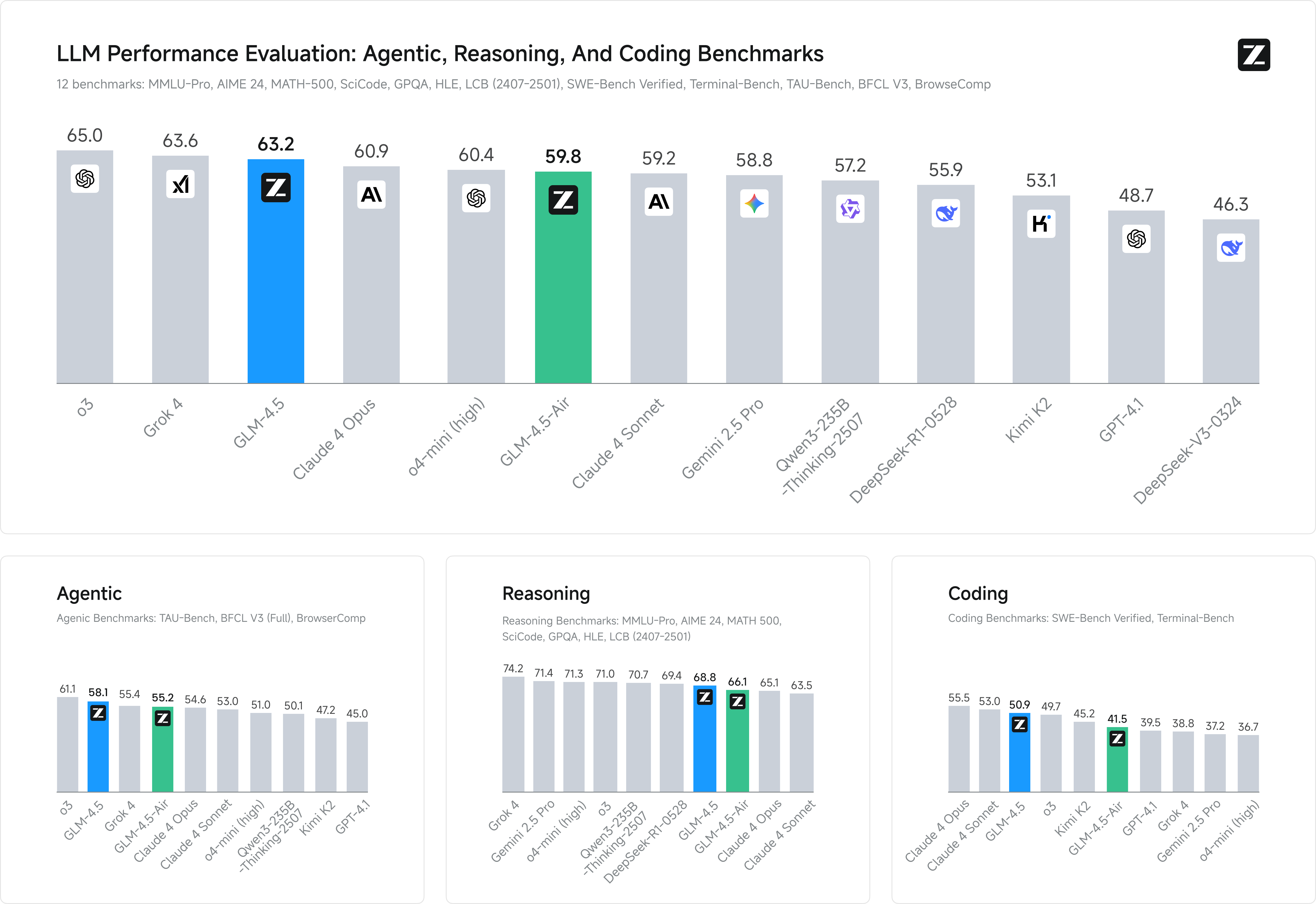
According to data released by Z.ai, the GLM-4.5 series performs excellently on 12 industry-standard benchmark tests (including MMLU, GSM8K, HumanEval, etc.):
- GLM-4.5: Average score of 63.2, ranking third globally among all models and first among open-source models.
- GLM-4.5-Air: Average score of 59.8, leading among models with tens of billions of parameters.
In specific capabilities, the GLM-4.5 series also stands out:
- Coding ability: Scored 64.2 on the SWE-bench Verified evaluation, surpassing GPT-4.1 and DeepSeek.
- Context window: Supports up to 128k input context and 96k output context, suitable for long document processing and complex programming tasks.
4. Agent-Native Capabilities
GLM-4.5 integrates the core capabilities of Agents (such as reasoning, planning, action) directly into the model architecture, achieving "native Agent" functionality. This means the model can:
- Autonomously perform multi-step task decomposition and planning.
- Seamlessly integrate and invoke external tools and APIs.
- Manage complex workflows and data visualization tasks.
- Support a complete “perception-action” cycle.
This design paradigm simplifies Agent application development, allowing developers to reduce reliance on external scheduling and flow control code and focus more on business logic implementation.
5. Efficiency, Speed, and Openness
The GLM-4.5 series sets new standards in inference efficiency and openness:
- Inference speed: Leveraging techniques such as Multi-Token Prediction (MTP) and Speculative Decoding, the high-end API generation speed exceeds 100 tokens/sec, reaching up to 200 tokens/sec, a 2.5 to 8 times improvement over previous models.
- API pricing: Extremely competitive pricing, as referenced in the pricing table. Uses tiered pricing, with the most expensive tier at 4 RMB per 1M input tokens and 16 RMB per 1M output tokens (original price, currently discounted). Versions marked with "X" are accelerated versions with presumably no difference in performance.
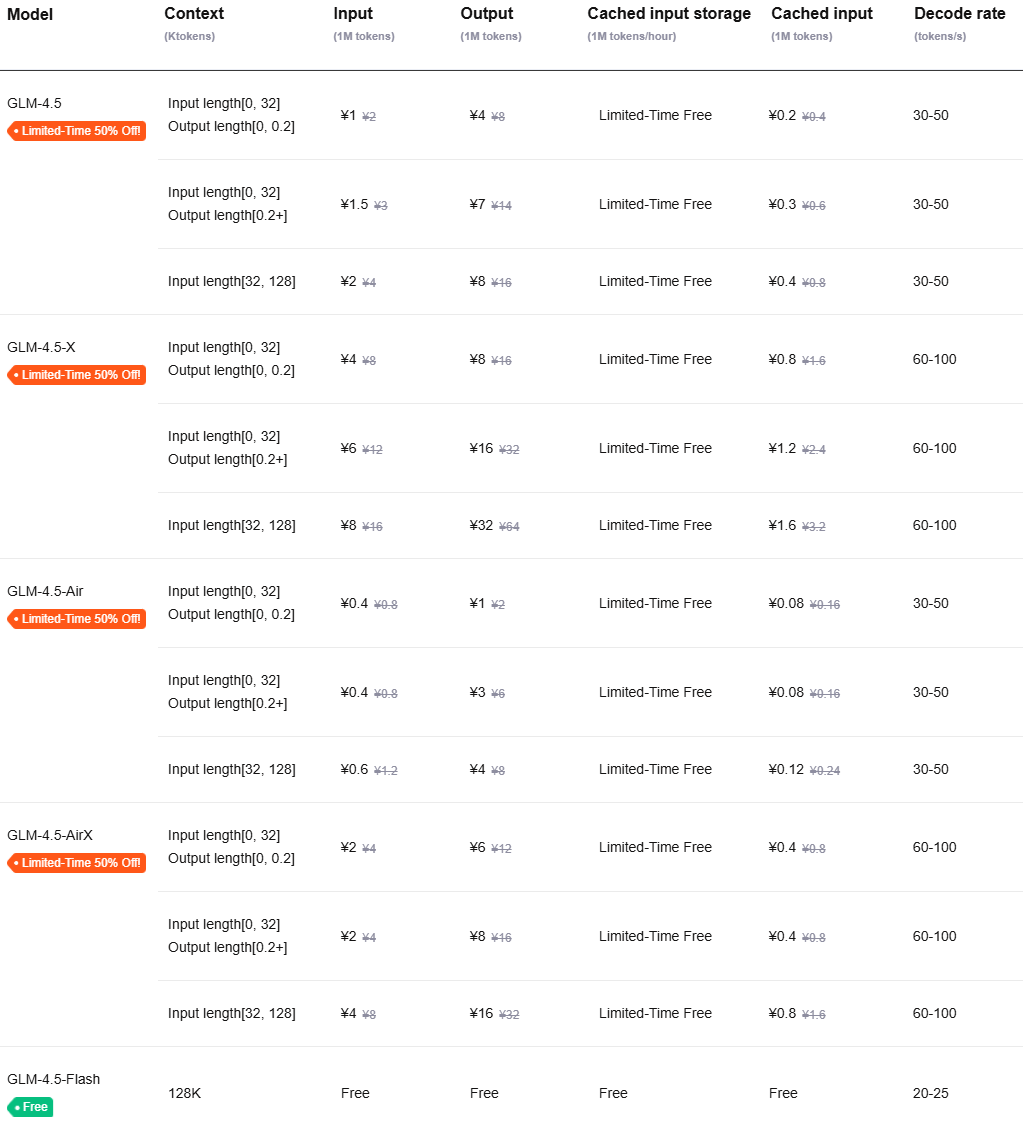
- Open-source license: The entire series, including base models, hybrid reasoning models, and FP8 quantized versions, are fully open-source under the Apache-2.0 license, permitting unlimited commercial use and secondary development.
- Ecosystem support: The models have been deeply integrated into mainstream LLM frameworks such as
transformers,vLLM, andSGLang, with complete code, tool parsers, and inference engines available on GitHub and Hugging Face, facilitating deployment, fine-tuning, and localization for developers.
6. Core Technical Innovations
The performance boost of GLM-4.5 comes from several technical innovations:
- Multi-Token Prediction (MTP): A specialized layer for speculative decoding that significantly improves inference speed on both CPU and GPU.
- Unified Architecture: Integration of inference, encoding, and multi-modal perception-action workflows within a unified framework.
- Large-scale Pretraining: The model is trained on datasets with up to 15 trillion tokens, laying a foundation for strong generalization ability.
- RLHF and the “Slime” system: Uses advanced reinforcement learning framework (Slime) with hybrid synchronous/asynchronous training and mixed precision rollout to efficiently optimize Agent workflows.
Conclusion
Zhipu AI’s GLM-4.5 series achieves significant balance between performance, efficiency, and openness, providing the open-source community with a powerful and easy-to-use foundational model. Its hybrid reasoning mode and native Agent capabilities lay a solid foundation for developing next-generation intelligent applications. Through comprehensive open-source release and robust support for mainstream development ecosystems, the GLM-4.5 series not only pushes technological boundaries but also creates new opportunities for global developers and researchers.
FAQ
1. What are the major improvements of GLM-4.5 compared to the previous GLM-4 model?
GLM-4.5 upgrades the architecture to MoE, greatly enhancing parameter efficiency. It also introduces hybrid reasoning mode, natively integrates Agent capabilities, and achieves significant improvements in inference speed, tool invocation success rates, and context window length.
2. Can individual developers deploy GLM-4.5 locally?
Yes, the GLM-4.5-Air version is optimized to run on mainstream consumer GPUs (32-64GB VRAM). The official release includes all related code and model weights with detailed deployment documentation.
3. How to experience the GLM-4.5 model?
Users can try it online via the official platform chat.z.ai, or download model weights from Hugging Face for local deployment. The API service also offers highly competitive pricing to facilitate large-scale experimentation.
4. What application scenarios is GLM-4.5 suitable for?
This series is especially suitable for Agent applications requiring multi-step reasoning and planning, code generation and analysis, long document summarization and Q&A, and automated integration of complex toolchains. It is also an ideal choice for enterprises looking to build privatized LLMs or Agents.
References
Source Notice
This article is published by merchmindai.net. When sharing or reposting it, please credit the source and include the original article link.
Original article:https://merchmindai.net/blog/en/post/glm-4-5-overview



