Gemma 4 发布解读:Google 开放模型的新方向与实用看点
Google 于 2026 年 4 月 2 日发布 Gemma 4。本文基于官方发布页、Google Blog 与 Hacker News 讨论,梳理模型规格、Apache 2.0 许可、长上下文、多模态与本地部署价值。

2026 年 4 月 2 日,Google 正式发布 Gemma 4。如果只用一句话概括这次更新,那么它不是一次“参数更大一点”的常规迭代,而是 Google 对开放模型路线的一次重新定调:更强调 agentic workflow、本地运行、多模态输入,以及更宽松的 Apache 2.0 许可。
本文基于官方资料与 Hacker News 社区讨论,回答四个最实际的问题:
- Gemma 4 到底是什么,和前几代相比重点变了什么;
- 四个模型规格分别适合什么场景;
- 官方 benchmark 应该怎么读,哪些信息不能过度解读;
- 开发者与团队负责人现在是否值得关注 Gemma 4。
Gemma 4 是什么?
根据 Google DeepMind 官方页面,Gemma 4 是一组“基于 Gemini 3 研究与技术构建”的开放模型,主打 intelligence-per-parameter,也就是在更可控的硬件开销下,尽量逼近前沿模型的能力。
和很多只强调聊天能力的开放模型不同,Google 这次把 Gemma 4 的定位写得很明确:
- 面向 高级推理;
- 面向 agentic workflows;
- 面向 本地和边缘部署;
- 面向 多模态理解 与更长上下文处理。
这意味着 Gemma 4 的目标不只是“做一个还能用的开源替代品”,而是试图覆盖从手机、IoT 到开发者工作站的一整条产品链路。
四个规格怎么选?先看定位比看参数更重要

官方这次发布了四个规格:E2B、E4B、26B MoE、31B Dense。
| 模型 | 官方定位 | 更适合谁 |
|---|---|---|
| E2B | 极致计算与内存效率 | 手机、边缘设备、离线轻应用 |
| E4B | 轻量多模态与低延迟 | 本地助手、语音/视觉入口、小型端侧产品 |
| 26B MoE | 更看重速度与 agentic workflow | 本地推理、工具调用、开发工作流 |
| 31B Dense | 更看重质量与微调潜力 | 研究、微调、复杂推理与代码场景 |
从官方介绍看,这四个模型其实分成两类:
这里有一个值得单独解释的命名细节:E2B 里的 E 指的是 Effective,也就是“有效参数规模”。Google 在 Gemma 4 官方博客中直接把它写成 Effective 2B 和 Effective 4B,这和传统只看总参数量的命名方式不太一样。
这类命名想强调的不是“模型物理上总共有多少参数”,而是在实际运行时,模型以多大的有效规模参与推理。对开发者来说,这个差别很重要,因为它更接近真实部署时的资源占用、内存压力和端侧可运行性,而不只是一个方便比较的参数标签。
从 Google 之前对 Gemma 3n 的文档说明看,E 前缀也被用来表示模型可以在较低的 effective parameters 规模下运行。因此放到 Gemma 4 的语境里,E2B / E4B 可以理解为:它们更强调运行效率和设备适配性,而不是单纯追求“总参数更大”。
E2B / E4B:边缘端优先
Google DeepMind 在官网上直接把 E2B 和 E4B 描述为面向 mobile and IoT devices。官方强调,这两个模型可以离线运行在手机、Raspberry Pi、Jetson Orin Nano 一类设备上,并主打低延迟。
这部分最值得注意的是两点:
- 不是只做文本。官方写明全系支持图像和视频理解,而 E2B、E4B 还支持原生音频输入。
- 不是只做演示。如果一个模型从设计上就是给移动端和边缘端准备的,那么它对隐私、本地处理和弱网场景的吸引力会明显高于“能勉强压缩下来运行”的大模型。
26B MoE / 31B Dense:工作站与本地服务器优先
大模型部分则更像是 Google 给“本地高性能开放模型”交出的一张答卷。
根据 Google Blog 的说法:
- 26B 是 Mixture of Experts 架构,推理时只激活总参数中的一部分,更关注延迟与效率;
- 31B 是 Dense 架构,更强调原始质量和作为微调底座的价值;
- 未量化的 bfloat16 权重可放在单张 80GB H100 上;
- 量化版本则瞄准消费级 GPU、本地 IDE、代码助手和 agent workflow。
如果讨论重点是“本地跑代码助手是否靠谱”,26B 和 31B 会比小模型更值得看。
这次发布最重要的 4 个信号
1. Apache 2.0 许可,可能是这次最关键的变化
官方博客明确写到,Gemma 4 改为 Apache 2.0 许可。对很多开发团队来说,这甚至比 benchmark 本身更重要。
为什么?因为过去大家对“open model”最敏感的问题之一,就是:
- 能不能商用;
- 能不能放心做二次开发;
- 能不能在自己的基础设施里长期部署;
- 许可条款会不会成为后续合规风险。
Apache 2.0 至少在工程落地层面给了更清晰的答案。你仍然要自己处理部署、安全、数据和输出责任,但许可摩擦显著降低了。
从 HN 讨论看,社区对这一点也非常敏感。高赞评论里最常出现的关键词之一就是:“Apache 2.0 is a big shift.”
2. Agentic workflow 不再是附加项,而是主叙事
Google 在官方文案里多次强调 Gemma 4 面向 agentic workflows,并明确点出:
- 原生 function calling;
- 结构化 JSON 输出;
- 原生 system instructions;
- 更适合让模型与外部工具和 API 协同工作。
这说明 Google 不是把 Gemma 4 当成单纯的聊天模型,而是把它视为可以被嵌入工作流、工具链和产品逻辑里的开放底座。
如果项目正在面向这些方向,Gemma 4 会更值得关注:
- 本地代码助手;
- 企业内部自动化代理;
- 文档处理与结构化抽取;
- 需要离线、可控推理的多步工作流。
3. “多模态 + 长上下文 + 多语言”是组合拳
Gemma 4 的另一个亮点不是单个特性,而是这些能力被同时塞进了一个相对容易部署的开放模型家族里:
- 多模态:图像、视频理解,全系支持;
- 音频输入:E2B、E4B 原生支持;
- 长上下文:边缘模型 128K,上层模型最高 256K;
- 多语言:官方称原生训练覆盖 140+ 语言。
这组能力放在一起,意味着 Gemma 4 不只是“开源聊天机器人底座”,而是更接近一个能做真实应用拼装的模型组件库。
举个很现实的例子:如果要做一个本地知识助手,既要读长文档、又要做 OCR/图像理解,还希望后续接语音入口,那么 Gemma 4 的路线图比传统单模态小模型更完整。
4. Google 正在明显强化“本地优先”的开放模型叙事
官方博客反复强调 Gemma 4 可以运行在:
- Android 设备;
- Raspberry Pi;
- Jetson Orin Nano;
- 开发者笔记本和工作站;
- 云端生产环境。
这背后的信号很明确:Google 并不想把 Gemma 4 讲成“只能在云上试试看”的开放模型,而是希望它成为 local-first AI 的一部分。
这对开发者有两个直接吸引力:
- 隐私与数据控制:某些 OCR、翻译、内部文档问答、代码分析场景,并不想把数据送进第三方 API。
- 成本与延迟:一旦任务稳定、模型足够好,本地推理对频繁调用的场景可能更可控。
官方 benchmark 很亮眼,但该怎么看才不误判?
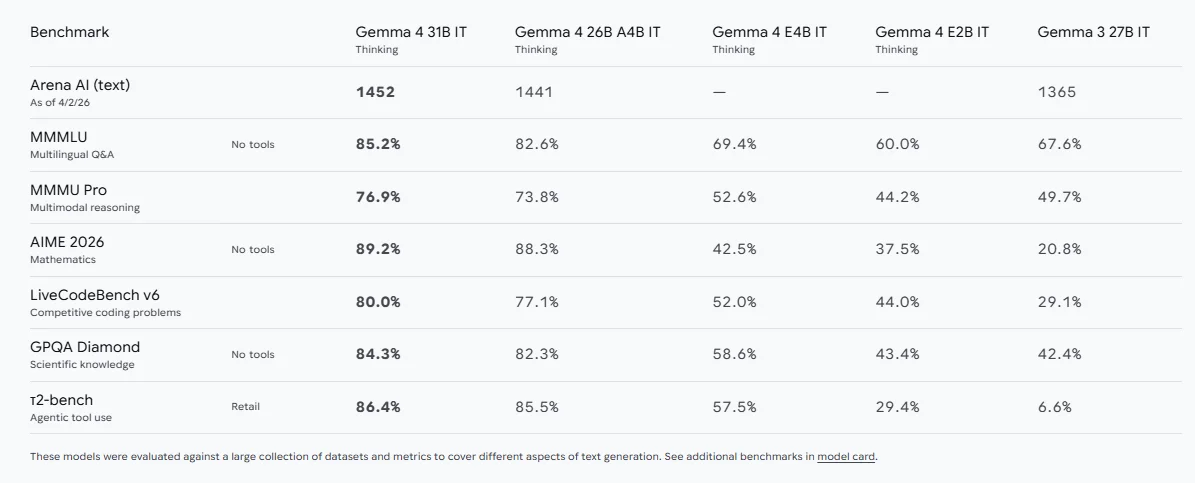
Google DeepMind 官方页面给出了多项指标,包括:
- Arena AI(文本)中 31B IT Thinking 为 1452;
- MMMLU 多语言问答中 31B 为 85.2%;
- MMMU Pro 多模态推理中 31B 为 76.9%;
- AIME 2026 数学中 31B 为 89.2%;
- LiveCodeBench v6 中 31B 为 80.0%;
- tau2-bench 零售工具使用中 31B 为 86.4%。
单看趋势,官方想传达的信息很清楚:
- 31B 和 26B 的能力已经不只是“够用”,而是在很多任务上接近前排;
- E2B 和 E4B 不只是轻量模型,而是在小体积里尽量保住推理与多模态能力;
- Gemma 4 不再只强调文本聊天,而是把推理、代码和工具使用一起纳入卖点。
但这里要特别提醒一句:benchmark 只能说明模型的上限和方向,不等于真实生产收益。
这也是 HN 讨论里一个非常典型的观点。有评论直说,公开 benchmark 往往“有参考价值,但不一定代表现实使用体验”,最终还是要看具体任务集和私有评测。
这个判断非常务实。对团队来说,真正应该比较的是:
- 任务成功率;
- 人工返工比例;
- 工具调用稳定性;
- 长上下文下的成本与速度;
- 量化后能力衰减是否还能接受。
HN 讨论反映了哪些真实关切?
截至本文撰写时,也就是 2026 年 4 月 3 日,这条 Hacker News 讨论串显示约 1211 points、360 comments。从讨论内容看,社区关注点大致集中在四类。
1. 许可变化比很多人预期中更重要
不少评论直接把 Apache 2.0 视为 Gemma 4 的最大卖点之一。原因很简单:开放模型社区过去并不缺“能下载”的模型,缺的是 真正降低商用和集成摩擦的许可条件。
2. 本地部署的想象空间很大
讨论里能明显看到一类典型需求:
- 本地 OCR;
- 文档处理;
- 翻译;
- 文件整理;
- 代码辅助;
- 私有数据工作流。
这和官方的产品叙事是对齐的。Gemma 4 的吸引力,不只是“Google 也发开放模型了”,而是它试图覆盖很多原本只能在云端 API 上做的轻中量任务。
3. 早期体验和榜单成绩之间,大家依然保持谨慎
有开发者分享了首日实际测试结果,认为 Gemma 4 在某些代码场景里还不如其他同级模型稳定;也有人提醒,首发当天工具链、chat template、tool calling 支持常常还在快速修复中,不适合过早下结论。
这类讨论很有价值,因为它提醒我们区分两件事:
- 模型本身的潜力;
- 生态工具是否已经跟上。
一个模型的官方能力很强,不等于你今天在 llama.cpp、Ollama、某个量化版本或第三方前端里就能立即获得同等体验。
4. 社区仍然希望看到“私有任务上的真实对比”
HN 里另一条很务实的观点是:如果真正关心模型是否适合具体场景,就不要只看公共榜单,而要拿自己的任务去测。
这尤其适用于以下场景:
- 内部知识库问答;
- OCR 和版面解析;
- 代码改写与重构;
- 结构化信息提取;
- 多语言客服或翻译。
哪些团队应该优先关注 Gemma 4?
如果属于下面几类团队或项目,Gemma 4 值得尽快进入评估名单:
1. 想做本地优先 AI 产品的团队
比如桌面助手、移动端智能功能、私有知识助手、文档理解工具。Gemma 4 的边缘规格和大规格之间有比较自然的产品升级路径。
2. 对许可和数据控制很敏感的团队
Apache 2.0 对很多公司来说是重要加分项,尤其是那些不希望在商业化阶段重新评估模型许可风险的团队。
3. 需要多模态但又不想完全押注闭源 API 的开发者
Gemma 4 并不是“任何方面都最好”的万能答案,但它把图像、视频、音频、长上下文和工具调用放进了同一条开放模型线上,这本身就足够有吸引力。
现阶段也别高估 Gemma 4
一篇介绍文如果只讲优点,其实没有太大参考价值。Gemma 4 现在更适合被看作一条 值得认真评估的新选择,而不是所有场景的默认最优解。
你至少还要留意这些现实问题:
- 首发阶段第三方推理栈的适配可能不稳定;
- 量化版本和原版模型的表现会有差距;
- 多模态、长上下文和工具调用叠加后,对工程实现要求并不低;
- 许可更开放,不代表部署、审计和安全问题会自动消失。
换句话说,Gemma 4 的意义在于它让更多“本来只能靠闭源模型完成”的产品设想,开始具备了开放落地的可能性;但能不能变成好产品,仍然取决于评测方法、工程能力和具体场景。
结语
Gemma 4 是 Google 这两年开放模型路线里非常值得关注的一次发布。真正重要的,不只是它的 benchmark,也不只是它来自 Google,而是它把几个过去往往分散存在的优势放在了一起:
- 更明确的 Apache 2.0 许可;
- 更强的 agentic workflow 叙事;
- 更完整的多模态与长上下文能力;
- 更清晰的本地优先部署路线。
对于普通开发者,这意味着可以更认真地把它纳入本地实验栈; 对于团队负责人,这意味着应该尽快用真实任务跑一轮对比评测,而不是只看榜单决定方向。
Gemma 4 也许还不是开放模型竞赛的终点,但它很可能会成为 2026 年本地 AI 与开放模型讨论里的一个关键节点。
参考资料
来源声明
本文来自 merchmindai.net。分享或转载本文时,请注明出处,并附上原文链接。
原文链接:https://merchmindai.net/blog/zh/post/google-gemma-4-open-models-guide