从 GLM-5.1 到 Qwen3.6:中国模型开源为何变慢
围绕 GLM-5.1、MiniMax M2.7 与 Qwen3.6-Plus 的官方发布和社区反馈,分析中国模型厂商为何越来越常见先发 API、延后开放权重。

更新日期:2026 年 4 月 12 日
过去一年,中文大模型圈最鲜明的节奏之一,是“博客一发,权重就上”。Qwen、DeepSeek、Kimi、GLM、StepFun 轮番刷新开源社区的预期,也让很多开发者默认认为:中国模型厂商在旗舰模型上会持续扮演 open-weight 的主力。
但到了 2026 年春天,这个节奏开始出现明显变化。
GLM-5.1、MiniMax M2.7 和 Qwen3.6-Plus 三个样本,放在一起看特别有代表性。它们都把重点押在 agentic coding、长时程任务和真实工作流能力上;它们也都证明,中国厂商依然在前沿模型上保持极强竞争力。可与此同时,它们又共同指向另一件事:旗舰模型的发布时间,正在和 open-weight 发布时间逐渐脱钩。
更准确地说,今天越来越常见的模式不再是“模型一发布就同步开放权重”,而是:
- 先上线 API、Coding Plan 或官方托管服务。
- 再观察真实工作负载里的稳定性、价格与商业反馈。
- 最后决定是否开放权重、开放多大版本,以及采用多宽松的许可证。
这并不等于“中国厂商不再开源”。但它确实意味着,开源正在从默认同步动作,变成更谨慎、更分阶段的产品决策。
如果你想先看更广的行业背景,也可以先读我们之前写的 中国 LLM 现状观察;而从全球 open model 的角度看,Gemma 4 开源模型指南 也能帮助理解另一条不同路线。
1. GLM-5.1:最像“传统开源胜利”的那一个
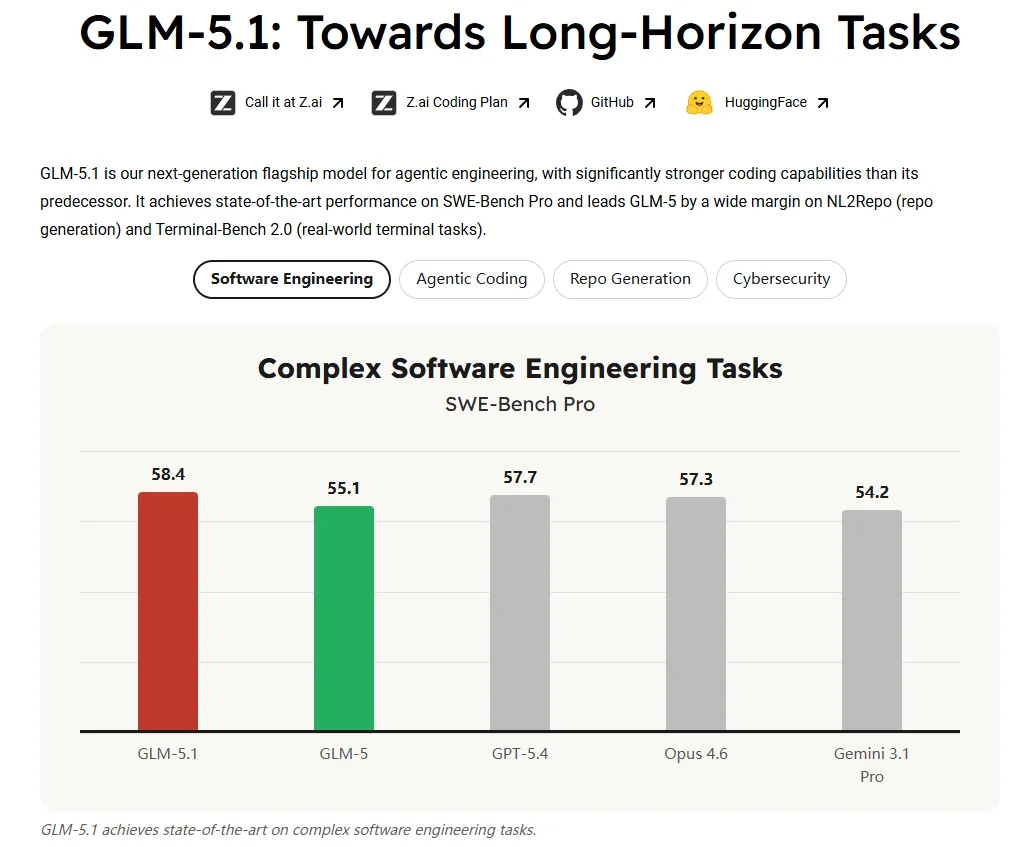
在这组三个样本里,GLM-5.1 其实最接近大家熟悉的那种 open model 叙事。
Hugging Face 上的 GLM-5.1 模型卡明确标注了 MIT 许可证,并把它描述为“面向 agentic engineering 的下一代旗舰模型”。模型卡强调的重点,不只是首轮回答更强,而是它在更长时程的 agent 任务中,能够持续拆解问题、调用工具、读取结果、修正策略,并在数百轮迭代后继续保持有效性。
这套叙事非常重要,因为它和 2025 年那种“谁聊天更像人、谁单轮推理更强”的竞争重点已经不一样了。GLM-5.1 代表的是另一种卖点:如果把模型放进真实工程工作流里,它能否长时间不掉线、不断改进,而不是几轮之后就进入性能平台期。
从官方给出的公开 benchmark 来看,GLM-5.1 也确实在向这个方向证明自己。Hugging Face 模型卡列出了 SWE-Bench Pro 58.4、NL2Repo 42.7、Terminal-Bench 2.0 63.5 等成绩,并直接把对标对象放在 Qwen3.6-Plus、MiniMax M2.7、Claude Opus 4.6、Gemini 3.1 Pro 和 GPT-5.4 旁边。这种写法本身就说明,智谱想强调的不是“我已经是便宜替代品”,而是“我已经进入同一层级的 agent/coding 比赛”。
社区反馈也基本延续了这个方向。
- 在 r/LocalLLaMA 的一条讨论 中,测试者认为
GLM-5.1在 OpenClaw 类型的真实 agent benchmark 上已经接近 Opus 4.6。 - 另一条关于本地部署的帖子里,用户更关注的也不是单轮分数,而是它在长流程工具调用里的稳定性。这说明社区对
GLM-5.1的兴趣,已经明显转向真实 agent harness 表现。来源 - 但反面的声音也不少。Hugging Face 社区里已经有人反馈,超过
100Ktoken 后性能会明显退化,也有人质疑官方展示的部分长上下文与浏览类 benchmark 是否能稳定复现。来源 1 来源 2
所以,GLM-5.1 给出的信号并不是“开源模型已经毫无代价地追平闭源模型”,而是更现实的一种状态:在 agentic coding 这条赛道上,open-weight 模型已经真正进入前排,但代价仍然是模型很大、推理成本不低、长上下文稳定性也仍有争议。
这也是为什么我会把 GLM-5.1 看成这波变化里的“基准样本”。它说明中国厂商还没有放弃旗舰开源;只是就算最积极的一方,也已经把开源叙事从“人人都能本地跑”转成了“开发者可以获得权重、生态可以围绕它构建,但真正高质量使用依旧有不低门槛”。
2. MiniMax M2.7:性能很强,但许可证让讨论迅速变味
如果说 GLM-5.1 代表的是“依然相信旗舰 open-weight 有战略价值”,那么 MiniMax M2.7 则更像另一种更谨慎的路径:愿意开放权重,但不愿意轻易放弃商业控制权。

MiniMax 在 2026 年 3 月 18 日的官方博客里,把 M2.7 定义为首个“深度参与自身进化”的模型。官方对它的描述相当激进:它不只是能写代码,而是能构建复杂 agent harness、维护 memory、调用复杂 skills、参与强化学习实验,甚至帮助优化下一轮模型的训练和评测流程。
博客里给出的几组关键数字也都指向“真实工作流”而不是纯聊天体验:
SWE-Pro 56.22%VIBE-Pro 55.6%Terminal Bench 2 57.0%GDPval-AA ELO 1495- 在
MLE Bench Lite三次 24 小时自主迭代实验里,平均奖牌率66.6%
这些指标共同服务于一个核心叙事:MiniMax 想把 M2.7 包装成“会自我改进的工作代理”,而不只是另一个强一点的文本模型。
从社区第一反应看,这个定位是奏效的。
- 在 r/LocalLLaMA 的发布讨论 里,很多人最感兴趣的并不是单个 benchmark 分数,而是博客所描绘的“模型参与自身迭代和评测”的工作流。
- 也有第三方测试者在 PinchBench / Kilo Bench 实测 中给出相对积极的评价,认为
M2.7更像一个为复杂任务优化的 agent 模型,而不是单纯追求表面速度的聊天模型。
但 MiniMax M2.7 的风向,很快就从“能力很强”转向了“这到底算不算 open source”。
截至 2026 年 4 月 12 日,Hugging Face 上的 MiniMax-M2.7 仓库 已经上线,不过页面标注的许可证不是常见的 MIT 或 Apache-2.0,而是 modified-mit。进一步看它的 LICENSE 文件,里面写得非常明确:非商业用途可以按 MIT 风格使用,但商业用途需要事先获得书面授权。
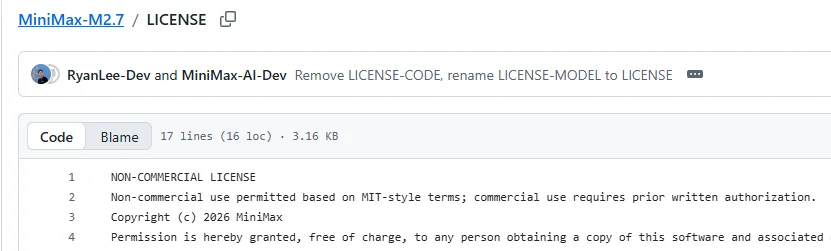
这就让整件事的含义发生了变化。
因为对很多开发者来说,真正关心的不是“我能不能下载到权重”,而是:
- 我能不能把它接进自己的产品?
- 我能不能在商业项目里微调、部署或托管?
- 我能不能放心把它放进长期可维护的技术栈?
也正因为如此,Hugging Face 社区里很快出现了对许可证的集中质疑。比如在 “No commercial use allowed in License?” 这个讨论下,用户的核心困惑就是:如果商业使用被严格限制,那么这更像一个“可下载试用版”,而不是开发者熟悉意义上的开放模型。
所以 M2.7 的特殊性在于,它既能被算作“开放了一部分东西”,又清楚地展示出另一种趋势:模型厂商愿意把权重放出来,但不再愿意像 2025 年那样,把最有商业价值的能力完全交给社区自由组合。
3. Qwen3.6-Plus:最典型的 API 先行、开源稍后
如果想找一个“开源节奏变慢”最直观的案例,Qwen3.6-Plus 可能就是目前最典型的样本。
阿里在 2026 年 4 月 1 日发布的官方博客里,明确把 Qwen3.6-Plus 定位成面向真实世界 agent 的新一代旗舰,并给出几个非常强的卖点:
- 默认
1M context window - 显著增强的
agentic coding - 更强的多模态感知与推理能力
- 立即通过 API 提供
博客末尾还有一句非常关键的话:“In the coming days, we will also open-source smaller-scale variants.” 这句话说明,Qwen 团队并没有否认开源,而是在明确告诉大家,这次的发布顺序已经变成了“先上线托管旗舰,再开放较小版本”。
问题在于,这个变化本身,就已经足够让社区情绪发生转向。
因为 Qwen 在过去一段时间里,一直是全球开发者心里最稳定的中文 open model 品牌之一。很多人对 Qwen 的预期,不只是“它会继续更新”,更是“它会像过去那样,把强版本尽快以 open-weight 形式交出来”。当这个预期被打破,哪怕只是阶段性打破,社区也会立刻把它解读为战略信号。
从讨论看,这种情绪非常明显。
- 在 Qwen3.6-Plus 的 LocalLLaMA 讨论 里,一部分用户承认它在真实 coding 工作流里的表现确实强,甚至有人说它比
Qwen3.5“更懂得怎么使用自己的智能”,尤其擅长在一条方案失败后主动切换思路。 - 但同一个帖子里,也有大量评论不再讨论性能本身,而是在追问:“为什么这次不是一开始就 open-weight?”“smaller variants 到底什么时候放?”“Qwen 是不是正在从开源旗手转向 API-first 商业化?”
- 另一条更直接的讨论 Is Qwen 3.6 going to be open weights? 也说明,社区最在意的问题之一,已经变成“权重到底什么时候出现”。
更关键的是,截至 2026 年 4 月 12 日,我还没有检索到 Qwen 官方 Hugging Face 组织下的 Qwen3.6 或 Qwen3.6-Plus 权重仓库。这里我刻意用的是更谨慎的表述:这不等于官方已经明确说“不开放”,但至少从公开可验证的信息看,4 月 1 日 的官方博客承诺,到 4 月 12 日 之间,社区仍处在等待阶段。
这就是为什么 Qwen3.6-Plus 的意义不只是“又一个更强模型来了”。它更像一个分水岭样本,告诉大家:在旗舰模型层面,Qwen 也开始把“产品化落地”放在“立即开放权重”之前。
4. 为什么会这样?我更倾向于这四个原因
这里需要特别说明:下面这部分不是厂商官方给出的统一解释,而是我基于这几次发布节奏、许可证设计和社区反馈做出的综合判断。
1. Agent 模型的真正价值,越来越依赖工作流而不是裸权重
2024 年很多模型比拼的是单轮回答,到了 2026 年,大家比的是:
- 能不能在终端里连续工作几个小时
- 能不能稳定调用工具
- 能不能维护 memory
- 能不能在 repo 级任务里持续收敛
一旦竞争焦点转向这些能力,模型价值就不再只在“权重”本身,还包括:
- scaffold
- harness
- prompt engineering
- skills / MCP 生态
- 生产环境中的限流、缓存与成本控制
这会让厂商更自然地优先推出 API 和官方工作台,因为这才是最完整、最可控、也最容易变现的产品形态。
2. 旗舰模型太贵,先用托管服务回收成本更现实
无论是 GLM-5.1 这种 700B+ 量级模型,还是 MiniMax M2.7 这种超大 MoE,真正高质量运行它们都不是“下载下来就完事”。推理硬件、上下文管理、并发、缓存、工具调用成本,都会迅速放大。
在这种情况下,先把最强版本留在 API 里,既能控制体验,也能更早回收算力和训练投入。对厂商来说,这不是背叛开源,而是非常朴素的商业现实。
3. 厂商想把“开放”做成分层,而不是一刀切
MiniMax M2.7 的许可证就是一个典型例子。它不是完全不放,也不是完全放开,而是选择了:
- 权重可以下载
- 非商业用途可以试
- 商业化仍然需要额外授权
这说明很多厂商正在尝试一种中间状态:既想保留社区扩散效应,又不想把商业控制权一次性交出去。
4. 社区对“开源”的定义,已经比厂商更严格
过去只要模型权重能下载,很多公司就会把它叫 open-source。今天开发者已经没那么容易买账了。大家会继续追问:
- 是不是 OSI 意义上的 open source?
- 商业使用是否受限?
- 微调、蒸馏、托管和再分发是否受限?
- 许可证会不会影响下游产品合规?
所以现在的争议,很多时候并不是厂商“有没有开放”,而是开放到什么程度,才能被开发者真正当成基础设施来信任。
5. 这对开发者意味着什么?
如果你是开发者、团队负责人,或者只是一个长期关注 open model 的重度用户,那么最近这波变化至少说明了三件事。
第一,以后不要再默认“官方博客发布日 = 权重开放日”。 这两件事已经越来越可能被拆开,而且间隔可能从几天拉长到几周,甚至更久。
第二,以后评估一个“开源模型”时,必须把许可证单独拿出来看。 权重可下载,不代表你就能放心商用;modified-mit 这种写法,看起来熟悉,实际约束可能非常重。
第三,真正重要的不只是模型有没有开源,而是它是否还在持续向开发者生态让利。 对很多团队来说,最关键的不是“我能不能下载到世界最强版本”,而是“我能不能拿到一个可商用、可微调、可本地部署、可长期维护的版本”。
从这个角度看,GLM-5.1、MiniMax M2.7、Qwen3.6-Plus 三者最大的区别,不只是性能路线不同,而是它们对开发者生态的“开放姿态”明显不同:
GLM-5.1更像“旗舰也愿意尽量开放”。MiniMax M2.7更像“开放权重,但商业边界收紧”。Qwen3.6-Plus更像“旗舰先 API 化,开源让位于产品发布顺序”。
常见问题
中国模型厂商是不是不再开源了?
不是。更准确的说法是:前沿旗舰模型的发布,正在和 open-weight 发布时间脱钩。 有些模型仍然开放,有些会延后开放,有些则通过许可证把商业使用限制得更严。
Qwen3.6-Plus 一定不会开源吗?
不能这么下结论。官方在 2026 年 4 月 1 日 的博客里明确写了,接下来几天会开源较小版本。更稳妥的表述是:截至 2026 年 4 月 12 日,公开可验证的官方权重仓库仍未出现,社区仍在等待。
MiniMax M2.7 算不算真正的开源模型?
这取决于你采用什么标准。如果只是“权重可下载”,那它当然算开放了一部分;但如果你关心 OSI 意义上的开放、商业自由使用和下游兼容性,那么 M2.7 当前的许可证显然比 MIT 或 Apache-2.0 更保守。
总结
如果只看模型能力,中国厂商并没有放慢脚步。恰恰相反,GLM-5.1、MiniMax M2.7、Qwen3.6-Plus 都说明,这一轮竞争已经从聊天机器人升级为真实 agent 工作流之争。
真正变化的,不是“模型有没有变强”,而是最强模型与开源社区之间的距离正在重新拉开一点点。
我更倾向于把这理解为一种新的分阶段开放策略,而不是简单的“转向闭源”。但对开发者生态来说,这仍然是一个值得警惕的信号:如果旗舰模型越来越多地选择 API-first、license-later、weights-when-stable,那么中国厂商过去在全球开源社区里建立起来的那种强信任关系,未来未必还能像 2025 年那样理所当然地延续下去。
相关资源
- GLM-5.1 Hugging Face 模型卡
- MiniMax M2.7 官方博客
- MiniMax M2.7 Hugging Face 模型页
- MiniMax M2.7 LICENSE
- Qwen3.6-Plus 官方博客
- LocalLLaMA:Qwen3.6-Plus
- LocalLLaMA:Is Qwen 3.6 going to be open weights?
- LocalLLaMA:MiniMax-M2.7 Announced!
- LocalLLaMA:Benchmarked MiniMax M2.7
- LocalLLaMA:GLM 5.1
- LocalLLaMA:GLM 5.1 crushes every other model except Opus in agentic benchmark
来源声明
本文来自 merchmindai.net。分享或转载本文时,请注明出处,并附上原文链接。
原文链接:https://merchmindai.net/blog/zh/post/glm-5-1-minimax-m2-7-open-model-shift