Gemma 4解説: Googleのオープンモデル戦略はどこへ向かうのか
Googleは2026年4月2日にGemma 4を公開しました。公式リリース、Google Blog、Hacker Newsの議論をもとに、モデル構成、Apache 2.0ライセンス、長文コンテキスト、マルチモーダル対応、ローカル実行の実用性を整理します。

2026年4月2日、Googleは Gemma 4 を正式に公開しました。ひと言で要約するなら、今回のアップデートは単なる「パラメータを少し増やしただけの順当な更新」ではありません。Googleがオープンモデル戦略を、agentic workflows、ローカル実行、マルチモーダル入力、そしてより扱いやすいApache 2.0ライセンス を軸に再定義したリリースだと言えます。
本記事では、公式情報とHacker Newsでの議論をもとに、次の4つの実務的な問いに絞って整理します。
- Gemma 4とは何か。従来世代と比べて何が変わったのか
- 4つのモデル仕様は、それぞれどんな用途に向いているのか
- 公式ベンチマークはどう読むべきか。どこを過大評価してはいけないのか
- 開発者や技術責任者は、いまGemma 4を追う価値があるのか
Gemma 4とは何か
Google DeepMindの公式ページによると、Gemma 4は「Gemini 3の研究と技術を基盤に構築された」オープンモデル群であり、重視されているのは intelligence per parameter です。つまり、ハードウェア負荷をより現実的に抑えつつ、できるだけフロンティアモデルに近い性能を目指すという考え方です。
チャット性能だけを前面に出すオープンモデルが多い中で、GoogleはGemma 4の位置づけをかなり明確に示しています。
- 高度な推論 を想定
- agentic workflows を想定
- ローカルおよびエッジ環境への展開 を想定
- マルチモーダル理解 と長いコンテキスト処理を想定
つまりGemma 4の狙いは、単に「一応使えるオープンソース代替」を出すことではありません。スマートフォンやIoTから、開発者向けワークステーションまでを含む、より広い製品導線をカバーしようとしているわけです。
4つのモデルはどう選ぶべきか。まずはパラメータ数より位置づけを見る

今回Googleが公開したのは、E2B、E4B、26B MoE、31B Dense の4種類です。
| モデル | 公式の位置づけ | 向いている対象 |
|---|---|---|
| E2B | 計算量とメモリ効率を最重視 | スマートフォン、エッジデバイス、オフラインの軽量アプリ |
| E4B | 軽量マルチモーダルと低遅延 | ローカルアシスタント、音声や画像の入口、小規模な端末内製品 |
| 26B MoE | 速度とagentic workflowを重視 | ローカル推論、ツール利用、開発者ワークフロー |
| 31B Dense | 品質とファインチューニング適性を重視 | 研究、ファインチューニング、複雑な推論やコード用途 |
公式説明を見る限り、この4モデルは大きく2系統に分けて考えたほうが理解しやすいです。
ここで単独で触れておきたい命名上のポイントがあります。E2Bの E は Effective を意味する という点です。GoogleはGemma 4の公式ブログで、これを Effective 2B、Effective 4B と明記しています。これは単純に総パラメータ数だけを見る従来の命名とは少し違います。
この命名が強調しているのは、「物理的に何個のパラメータを持つか」ではなく、実際の推論時にどの程度の有効なモデル規模が使われるか です。開発者にとってこの違いは重要です。なぜなら、単なる比較用のラベルよりも、実際の運用時におけるリソース消費、メモリ圧力、端末上での実行可能性に近い指標だからです。
Googleが以前公開していたGemma 3nのドキュメントでも、E プレフィックスは、より低い effective parameters 規模で動かせることを示すために使われていました。その流れでGemma 4のE2BとE4Bも、単に「総パラメータ数が大きいかどうか」より、実行効率とデバイス適合性を重視したモデル と理解するのが自然です。
E2B / E4B: エッジ優先
Google DeepMindは公式サイト上で、E2BとE4Bを mobile and IoT devices向け のモデルとして説明しています。スマートフォン、Raspberry Pi、Jetson Orin Nanoのようなデバイスでオフライン実行でき、低遅延であることが強調されています。
ここで特に注目したい点は2つあります。
- テキスト専用ではない こと。公式説明では、シリーズ全体が画像と動画の理解に対応し、さらにE2BとE4Bはネイティブな音声入力もサポートするとされています。
- 単なるデモ用途ではない こと。最初からモバイルやエッジ向けに設計されたモデルであれば、プライバシー重視、ローカル処理、通信が不安定な環境において、「無理やり圧縮して動かす大型モデル」より魅力が大きくなります。
26B MoE / 31B Dense: ワークステーションとローカルサーバー優先
大きいモデル群のほうは、Googleが考える 高性能なローカル向けオープンモデル の回答に近い印象です。
Google Blogによると、
- 26Bは Mixture of Experts アーキテクチャで、推論時には総パラメータの一部だけを有効化し、遅延と効率をより重視しています。
- 31Bは Dense アーキテクチャで、生の品質やファインチューニングの土台としての価値をより重視しています。
- 非量子化のbfloat16重みは、80GBのH100単体に載せられるとされています。
- 量子化版は、コンシューマ向けGPU、ローカルIDE、コードアシスタント、agent workflowを想定しています。
ローカルで動くコードアシスタントが現実的かどうかを考えるなら、小型モデルよりも26Bと31Bのほうが注目に値します。
今回のリリースで特に重要な4つのシグナル
1. Apache 2.0ライセンスは、今回最大の変化かもしれない
公式ブログでは、Gemma 4が Apache 2.0 ライセンスに切り替わったことが明記されています。多くの開発チームにとって、これはベンチマークそのもの以上に重要です。
なぜなら、これまで「オープンモデル」に対して多くの人が気にしてきたのは、次のような点だからです。
- 商用利用できるのか
- 安心して二次開発できるのか
- 自社インフラに長期的に載せられるのか
- ライセンス条項が後からコンプライアンスリスクにならないか
少なくともエンジニアリング実装の観点では、Apache 2.0はより明確な答えを与えてくれます。もちろん、デプロイ、安全性、データ管理、出力責任は各チームで対応する必要がありますが、ライセンス面の摩擦はかなり下がります。
Hacker Newsの議論でも、この点に対する反応は非常に敏感でした。高評価コメントで何度も見かけた表現のひとつが、"Apache 2.0 is a big shift." です。
2. Agentic workflowは付加機能ではなく、中心的な物語になった
Googleは公式文言のなかで、Gemma 4を agentic workflows 向けと何度も位置づけています。さらに、次のような機能を明示的に挙げています。
- ネイティブなfunction calling
- 構造化JSON出力
- ネイティブなsystem instructions
- 外部ツールやAPIと協調しやすい設計
これは、GoogleがGemma 4を単なるチャットモデルとして見ていないことを示しています。ワークフロー、ツールチェーン、製品ロジックに組み込めるオープンな基盤モデルとして扱っているわけです。
次のような方向性のプロジェクトでは、Gemma 4を追う価値が一段と高くなります。
- ローカルコードアシスタント
- 社内自動化エージェント
- 文書処理や構造化抽出
- オフライン性や制御性が求められる多段ワークフロー
3. 「マルチモーダル + 長文コンテキスト + 多言語」はセットで見るべき
Gemma 4のもうひとつの強みは、単独の機能というより、比較的展開しやすいオープンモデル群の中に、これらの能力がまとめて入っていることです。
- マルチモーダル: シリーズ全体で画像と動画理解に対応
- 音声入力: E2BとE4Bでネイティブ対応
- 長文コンテキスト: エッジ向けモデルで128K、上位モデルで最大256K
- 多言語: Googleによれば、140以上の言語を含むデータでネイティブ学習
これらをまとめて見ると、Gemma 4は単なる「オープンソースのチャットボット用ベースモデル」ではありません。実際のアプリケーションを組み立てるための部品群に近づいています。
現実的な例を挙げると、ローカルのナレッジアシスタントを作りたい場合、長文ドキュメントを読み、OCRや画像理解も行い、将来的に音声インターフェースも接続したいという要件が出てきます。そうしたとき、Gemma 4のロードマップは従来の単一モダリティ小型モデルよりもずっと揃っています。
4. Googleは「ローカル優先」のオープンモデル物語を明確に強めている
公式ブログでは、Gemma 4が次の環境で動作できることを繰り返し強調しています。
- Androidデバイス
- Raspberry Pi
- Jetson Orin Nano
- 開発者向けノートPCやワークステーション
- クラウドの本番環境
この背後にあるメッセージは明確です。GoogleはGemma 4を、「クラウド上で少し試せるだけのオープンモデル」として語りたいのではありません。local-first AI の一部として位置づけようとしているのです。
これは開発者にとって、少なくとも次の2点で魅力があります。
- プライバシーとデータ管理: OCR、翻訳、社内文書のQ&A、コード解析などでは、データを第三者APIへ送信したくないケースがあります。
- コストと遅延: ワークロードが安定し、モデル性能が十分であれば、頻繁に呼び出す処理はローカル推論のほうが制御しやすい場合があります。
公式ベンチマークは非常に目を引くが、どう読めば判断を誤らないか
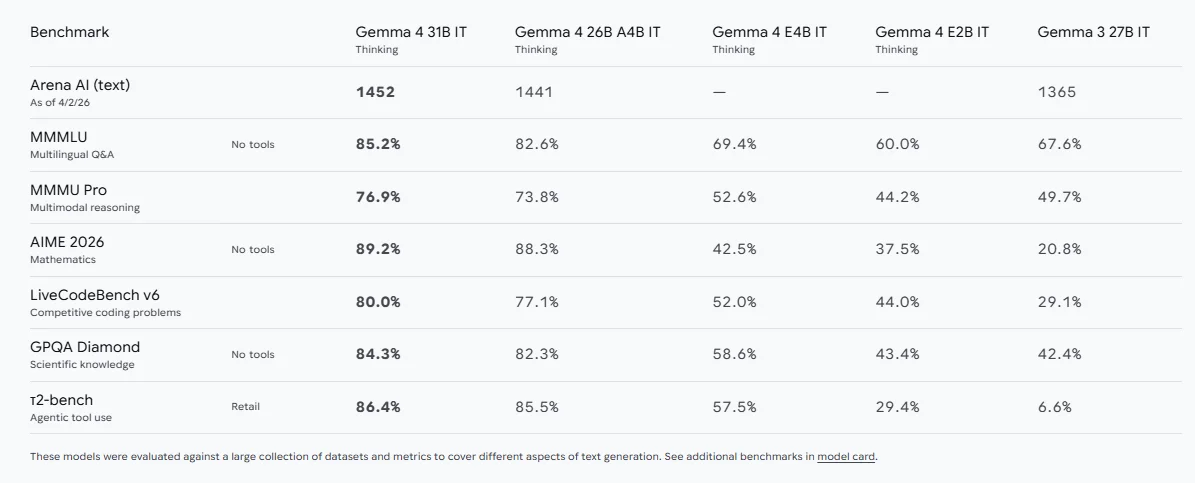
Google DeepMindの公式ページでは、たとえば次のような指標が掲載されています。
- Arena AI(テキスト)で31B IT Thinkingが1452
- 多言語QAのMMMLUで31Bが85.2%
- マルチモーダル推論のMMMU Proで31Bが76.9%
- 数学のAIME 2026で31Bが89.2%
- LiveCodeBench v6で31Bが80.0%
- 小売ツール利用のtau2-benchで31Bが86.4%
傾向としてGoogleが伝えたいメッセージは明快です。
- 31Bと26Bは、もはや単に「十分使える」だけではなく、多くのタスクで上位に食い込む水準にある
- E2BとE4Bは、軽量モデルでありながら、推論力とマルチモーダル性をできるだけ維持しようとしている
- Gemma 4は、テキストチャット専用ではなく、推論、コード、ツール利用まで含めた価値を打ち出している
ただし、ここで特に強調しておきたいのは、ベンチマークはモデルの上限や方向性を示すものであって、そのまま本番での成果を保証するものではない という点です。
この視点はHacker Newsの議論でも典型的でした。公開ベンチマークには参考価値がある一方で、現実の使用感とは一致しないことも多く、最終的には自分たちのタスクで私的評価を回す必要がある、という意見です。
これは非常に実務的な考え方です。チームが本当に比較すべきなのは、次のような指標です。
- タスク成功率
- 人手による手戻り率
- ツール呼び出しの安定性
- 長文コンテキスト時のコストと速度
- 量子化後の性能低下が許容範囲かどうか
Hacker Newsの議論から見えた現実的な関心事は何か
本稿執筆時点、つまり 2026年4月3日 時点で、このHacker Newsスレッドにはおよそ 1211 points、360 comments が付いていました。議論内容を見ると、関心は大きく4つに分かれていました。
1. ライセンス変更は、多くの人が想定していた以上に重要
Apache 2.0を、Gemma 4最大級の魅力のひとつと見るコメントは少なくありませんでした。理由はシンプルです。オープンモデル界隈にこれまで不足していたのは、「ダウンロードできるモデル」ではなく、商用利用と組み込みの摩擦を本当に下げるライセンス条件 だったからです。
2. ローカル展開の余地がかなり大きい
議論では、次のような用途が繰り返し出てきます。
- ローカルOCR
- 文書処理
- 翻訳
- ファイル整理
- コード補助
- プライベートデータを扱うワークフロー
これはGoogleの製品ストーリーとも整合しています。Gemma 4の魅力は、単に「Googleもオープンモデルを出した」ことではありません。これまでクラウドAPIに寄りがちだった軽量から中量級のタスクを、オープンな形で支えようとしている点にあります。
3. 初期の実使用感とランキング成績の差には、引き続き慎重な見方がある
初日の検証結果を共有した開発者の中には、コード関連の一部タスクではGemma 4が他の同級モデルほど安定していないと感じた人もいました。一方で、リリース当日はツールチェーン、chat template、tool calling対応が急速に修正されている最中であり、結論を急ぐべきではないという指摘もありました。
この議論が有益なのは、次の2点を切り分ける重要性を思い出させてくれるからです。
- モデルそのものの潜在力
- 周辺ツールエコシステムが追いついているか
公式の能力アピールが強くても、今日の時点で llama.cpp、Ollama、特定の量子化版、あるいはサードパーティ製フロントエンドで同じ体験がすぐ得られるとは限りません。
4. コミュニティは依然として「自分たちの私有タスクでの実比較」を求めている
Hacker Newsでもうひとつ実務的だった意見は、本当にそのモデルが自分たちの用途に合うか知りたいなら、公開ランキングだけでは足りず、自前のタスクで試すべきだというものでした。
特に次のような場面では、その傾向が強くなります。
- 社内ナレッジベースQ&A
- OCRやレイアウト解析
- コード書き換えやリファクタリング
- 構造化情報抽出
- 多言語対応や翻訳
どのチームがGemma 4を優先的に見るべきか
次のいずれかに当てはまるチームやプロジェクトなら、Gemma 4は早めに評価候補へ入れる価値があります。
1. ローカル優先AI製品を作りたいチーム
たとえばデスクトップアシスタント、モバイル向け知能機能、プライベートなナレッジアシスタント、文書理解ツールなどです。Gemma 4は、エッジ向け小型モデルから大きめのローカルモデルまで、比較的自然な製品拡張パスを持っています。
2. ライセンスとデータ管理に敏感なチーム
Apache 2.0は、多くの企業にとって重要な加点材料です。特に、商用化の後半であらためてモデルライセンスのリスクを見直したくないチームに向いています。
3. マルチモーダルは必要だが、クローズドAPIに全面依存したくない開発者
Gemma 4は、あらゆる面で最良の万能解というわけではありません。それでも、画像、動画、音声、長文コンテキスト、ツール利用をひとつのオープンモデル系列にまとめている点だけでも十分魅力的です。
現時点ではGemma 4を過大評価しすぎないことも大切
紹介記事が長所だけを並べるのでは、あまり参考になりません。現時点のGemma 4は、真剣に評価する価値のある新しい選択肢 と見るのが適切であって、すべての用途における既定の最適解とはまだ言えません。
少なくとも次のような現実的な論点には注意が必要です。
- リリース初期は、サードパーティ製推論スタックの対応が安定しない可能性がある
- 量子化版と元のモデルでは挙動に差が出る
- マルチモーダル、長文コンテキスト、ツール利用を組み合わせると、実装難度は決して低くない
- ライセンスがより開かれたからといって、デプロイ、監査、安全性の課題が自動で消えるわけではない
言い換えれば、Gemma 4の意義は、これまでクローズドモデルでしか実現しづらかった製品構想に対して、オープンな実装可能性を広げたことにあります。ただし、それが良い製品になるかどうかは、評価方法、実装力、そして具体的なユースケースに依然として左右されます。
まとめ
Gemma 4は、この2年間のGoogleのオープンモデル戦略の中でも特に注目すべきリリースです。重要なのは、ベンチマークが高いことだけでも、Google製であることだけでもありません。これまで別々に存在しがちだった複数の強みを、Gemma 4がひとつにまとめてきたことです。
- より明確なApache 2.0ライセンス
- より強いagentic workflowの物語
- より揃ったマルチモーダル対応と長文コンテキスト性能
- よりはっきりしたローカル優先の展開路線
個人開発者にとっては、ローカル実験環境に本格的に組み込む価値が出てきたことを意味します。 技術責任者にとっては、公開ランキングだけで方向を決めるのではなく、実タスクで早めに比較評価を回すべきだという意味になります。
Gemma 4がオープンモデル競争の終着点になるとは限りませんが、2026年のローカルAIとオープンモデルをめぐる議論において、重要な節目のひとつになる可能性はかなり高いでしょう。
参考資料
出典について
この記事は merchmindai.net に掲載された内容です。共有または転載する場合は、出典と元記事のリンクを明記してください。
元記事リンク:https://merchmindai.net/blog/ja/post/google-gemma-4-open-models-guide



