DeepSeek V4 预览版上线:1M 上下文、Flash/Pro 双模型与最新 API 价格
截至 2026 年 4 月 24 日,DeepSeek 已在 API 文档和 Hugging Face 上公开 DeepSeek V4 系列。本文梳理 Flash/Pro 两个模型、1M 上下文、思考模式、API 价格与开源权重信息。

截至 2026 年 4 月 24 日,DeepSeek 已在官方 API 文档和 Hugging Face 上公开 DeepSeek V4 系列。按照 Hugging Face 模型卡的表述,这一代目前属于 preview version。目前公开的信息显示,API 侧提供 deepseek-v4-flash 和 deepseek-v4-pro 两个模型名,开源侧则同步放出了 Flash / Pro 的 Base 与 Instruct 权重。
根据目前已经公开且可直接核实的信息,DeepSeek V4 这次更新的重点主要包括四项:1M 上下文窗口、默认开启的思考模式、Flash/Pro 双层产品线,以及已经上线的 API 定价。这些信息基本对应了模型的接入方式、能力边界和调用成本。
这次实际上发布了什么?
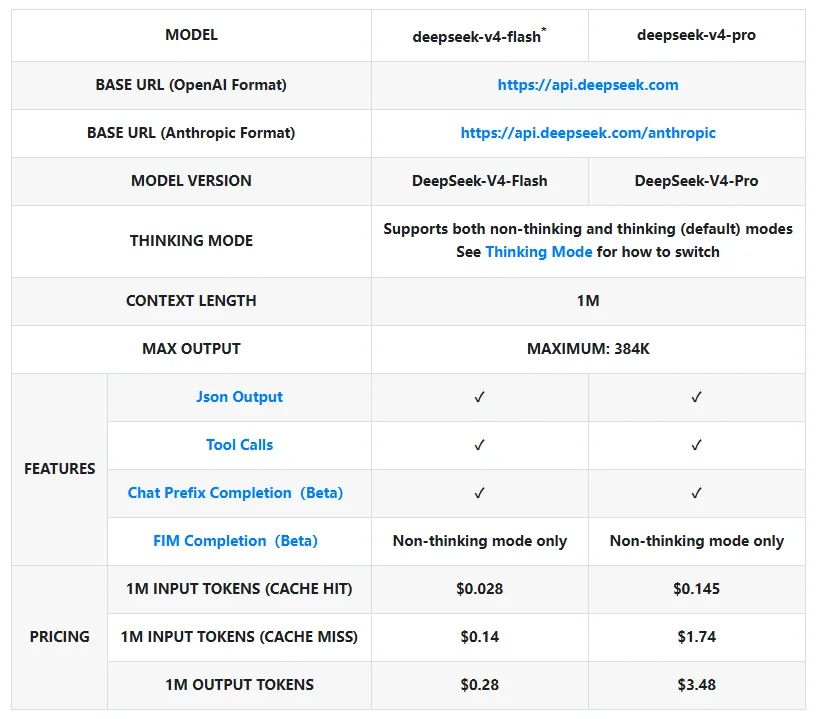
根据 DeepSeek API 文档的“模型 & 价格”页面,目前已经公开的 V4 API 模型包括:
deepseek-v4-flashdeepseek-v4-pro
文档显示,这两个模型都支持 OpenAI 格式 和 Anthropic 格式 的接入方式;两者都支持 思考模式,而且默认就是开启状态;上下文长度统一为 1M tokens,最大输出长度为 384K tokens。此外,JSON Output、Tool Calls、对话前缀续写(Beta)也都已经在 V4 上可用,FIM 补全(Beta) 则仅在非思考模式下支持。
这表明 DeepSeek V4 已经不只是研究型号,而是进入了 可调用 API 的产品阶段。
思考模式默认开启,旧模型名将逐步弃用
DeepSeek 的 Thinking Mode 文档给出的信息也比较明确。V4 支持两类显式控制:
thinking.enabled / disabled用于切换思考模式reasoning_effort用于控制推理强度,公开文档列出high和max
文档写明,思考模式默认启用。普通请求的默认 effort 是 high,某些复杂 agent 请求会自动提升到 max。兼容层面上,low 和 medium 会被映射到 high,xhigh 会被映射到 max。
另一个值得注意的变动是兼容命名。DeepSeek 在价格页注明,deepseek-chat 与 deepseek-reasoner 这两个模型名将在未来弃用;出于兼容考虑,它们当前分别对应 deepseek-v4-flash 的非思考模式和思考模式。如果团队现在还在旧模型名上做集成,这条信息需要尽快关注。
Hugging Face 上已经有 4 个公开仓库
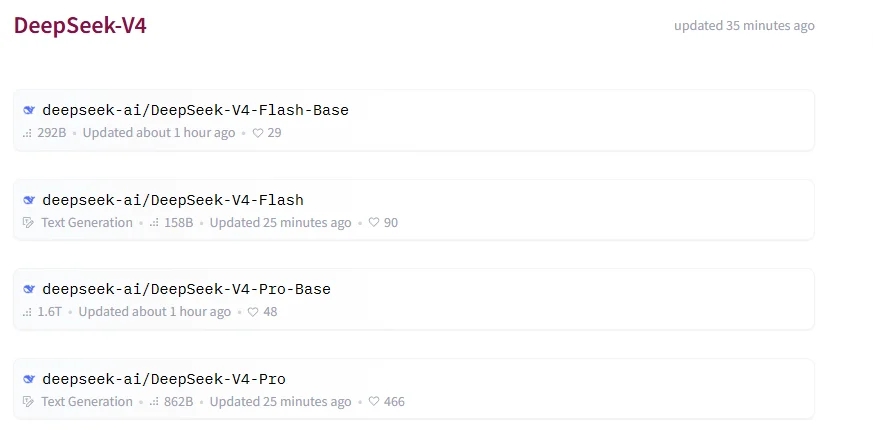
截至本文写作时,DeepSeek 在 Hugging Face 的 DeepSeek-V4 collection 中已经公开了 4 个仓库:
DeepSeek-V4-Flash-BaseDeepSeek-V4-FlashDeepSeek-V4-Pro-BaseDeepSeek-V4-Pro
其中,DeepSeek-V4-Pro 模型卡给出的官方参数信息如下:
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 精度 |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
模型卡将 V4 明确描述为两款 Mixture-of-Experts(MoE) 语言模型,并说明 Pro 与 Flash 都支持百万 token 级上下文。对希望本地部署或自托管的团队来说,这一点很关键,因为这意味着 V4 不只有 API 版本,权重本身也已经公开。
另外,模型卡还写明,这批仓库与模型权重采用 MIT License。官方同时提供了 encoding 与 inference 目录,用于说明消息编码、权重转换和本地运行方式。
API 价格已经公开,Flash 和 Pro 差异非常明显
当前价格页显示,DeepSeek V4 的价格分层也很清晰:
| 模型 | 输入价格(缓存命中) | 输入价格(缓存未命中) | 输出价格 |
|---|---|---|---|
| deepseek-v4-flash | 0.2 元 / 百万 tokens | 1 元 / 百万 tokens | 2 元 / 百万 tokens |
| deepseek-v4-pro | 1 元 / 百万 tokens | 12 元 / 百万 tokens | 24 元 / 百万 tokens |
从这组价格可以看出,Flash 更偏向高性价比和大规模调用,Pro 则是单价更高的高阶版本。如果任务以批量生成、轻量问答、结构化提取为主,Flash 的成本门槛会更低;如果更看重复杂推理、长上下文质量或高难度 agent 任务,Pro 的定价则更适合作为高性能档位的参考。
官方模型卡还透露了哪些技术信息?
Hugging Face 上的官方模型卡还给出了几条可以直接确认的技术信息:
- DeepSeek V4 采用混合注意力架构,结合了
CSA和HCA - 官方称,相比 DeepSeek-V3.2,V4-Pro 在 1M 上下文设置下,单 token 推理 FLOPs 降到 27%,KV cache 降到 10%
- 模型引入了
mHC(Manifold-Constrained Hyper-Connections) - 训练中使用了
Muon优化器 - 预训练数据规模超过 32T tokens
这些内容来自官方模型卡与技术报告入口,仍属于 DeepSeek 的技术说明;但从公开材料来看,这次发布不只是版本更新,也同步给出了新的架构和训练信息。
Evaluation Results 说明了什么?
DeepSeek-V4-Pro 模型卡还公开了一整组基础模型评测,对比对象是 DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base 和 DeepSeek-V4-Pro-Base。从这组结果来看,V4-Pro-Base 在知识、长上下文和部分高难知识问答任务上有较明显提升。
下面列几项更有代表性的结果:
| Benchmark | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|
| MMLU-Pro (EM) | 65.5 | 68.3 | 73.5 |
| MultiLoKo (EM) | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 28.3 | 30.1 | 55.2 |
| FACTS Parametric (EM) | 27.1 | 33.9 | 62.6 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| LongBench-V2 (EM) | 40.2 | 44.7 | 51.5 |
这组数字呈现出三个比较直接的趋势。
第一,V4-Pro-Base 的知识能力明显强于前代。像 Simple-QA verified 和 FACTS Parametric 这类更偏事实性和参数化知识的 benchmark,V4-Pro-Base 相对 V3.2-Base 的增幅较大。这至少表明,官方强调的知识能力提升在公开基准中有较明显的体现。
第二,长上下文方向的提升是连续的,而不是孤立的。LongBench-V2 从 40.2 提升到 51.5,配合模型卡里对 1M context 效率的说明,可以看出 V4 这一代的重点确实放在“更长上下文还能维持效果”这件事上。
第三,Flash 和 Pro 的定位差异也很清楚。Flash-Base 并不是一个“阉割到只能低成本跑量”的版本,它在多项知识和代码任务上已经高于 V3.2-Base;但 Pro-Base 仍然是上限更高的主力型号,尤其在知识问答、复杂考试类任务和长上下文任务上差距更明显。
当然,这组 Evaluation Results 也有一个很重要的阅读前提:它主要是基础模型之间的官方对比,不等于真实产品模式下的最终使用体验。尤其是 V4 这一代把“思考模式”和 effort 控制放到了默认接口层,实际 API 体验往往还会受到推理预算影响。
DeepSeek-V4-Pro-Max vs Frontier Models 结果说明了什么?
模型卡还给出了一张更受关注的对比表:DeepSeek-V4-Pro-Max vs Frontier Models。这里比较的是 DS-V4-Pro Max 与多家闭源前沿模型的结果,包括 Opus-4.6 Max、GPT-5.4 xHigh、Gemini-3.1-Pro High、K2.6 Thinking 和 GLM-5.1 Thinking。
其中几项最能代表定位的结果如下:
| Benchmark | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 84.4 |
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | 3206 |
| MRCR 1M (MMR) | 92.9 | - | 76.3 | 83.5 |
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.6 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 51.8 |
如果把这张表压缩成一句话,那就是:DeepSeek-V4-Pro-Max 在代码和部分工具/代理任务上已经非常接近,甚至在个别项目上超过主流闭源模型;但在最顶尖的综合知识与极限推理任务上,还没有形成全面领先。
这组结果大致反映出四点。
第一,DeepSeek 明显希望把它定位在开源阵营的第一梯队。模型卡原文直接将 DeepSeek-V4-Pro-Max 描述为“当前最好的开源模型”。从表中的分数看,这一定位有一定依据,尤其是在 LiveCodeBench、Codeforces、MCPAtlas Public 这类更偏代码和工具使用的基准上,V4-Pro-Max 的表现确实很有竞争力。
第二,它并不是在所有维度都追平闭源前沿模型。例如 MMLU-Pro、GPQA Diamond、HLE、Apex 这些更偏综合知识、科研级推理或极限难题的项目上,Gemini-3.1-Pro High 和 GPT-5.4 xHigh 仍然维持着更强的上界。也就是说,V4-Pro-Max 更像是“把差距显著缩小”,而不是“已经在全部高难任务上反超”。
第三,代码和工程工作流很可能是它当前最突出的强项。LiveCodeBench 93.5、Codeforces 3206,再加上 SWE Verified 80.6、Terminal Bench 2.0 67.9,这组分数组合说明 DeepSeek 这次不只是强调考试型 benchmark,也在突出编码、终端和 agent workflow 场景下的表现。
第四,长上下文和中文知识能力是它的重要差异化方向。Chinese-SimpleQA 的 84.4 分已经非常高,MRCR 1M 和 CorpusQA 1M 也说明 V4-Pro-Max 的百万 token 能力不是只停留在配置表里。对需要长文档处理、中文问答或本地知识场景的团队来说,这部分信息会比单纯看通用 benchmark 更有参考价值。
不过,这张 Pro-Max vs Frontier Models 表也需要保留一个前提:它是模型卡里的官方对照结果,不同厂商之间的评测设置、推理预算和工具配置并不一定完全一致。更合适的理解方式不是“DeepSeek 已经全面领先”,而是“DeepSeek 已经把开源模型与闭源前沿模型之间的差距压缩到了值得重点评估的程度”。
目前能确定的结论
根据当前已经公开的官方资料,至少有几项信息已经比较明确:
- DeepSeek V4 已经正式进入可用状态,因为 API 文档、价格页和 Hugging Face 仓库都已上线。
- 这一代至少有 Flash 和 Pro 两条线,并且同时覆盖 API 调用与公开权重。
- 1M 上下文和思考模式是 V4 的共同特征,不是某一个单独型号的附加能力。
- 旧的
deepseek-chat/deepseek-reasoner命名体系将逐步退出,迁移到 V4 命名基本已成定局。
对关注中国大模型更新节奏的读者来说,这次发布的意义在于:DeepSeek 已经把 V4 从“新一代模型代号”推进到了 文档、接口、价格和权重都同步公开 的阶段。接下来,市场更关心的问题大概率会转向真实效果、第三方部署生态,以及开发者在实际工作流中的首轮体验。
相关资源
来源声明
本文来自 merchmindai.net。分享或转载本文时,请注明出处,并附上原文链接。
原文链接:https://merchmindai.net/blog/zh/post/deepseek-v4-release-api-pricing-open-weights



