By GenCybers.inc•
DeepSeek V3.1发布综述:性能、价格与功能亮点
简要总结DeepSeek V3.1发布的主要性能、价格以及功能亮点,并对比同类主流大模型。

概述
DeepSeek V3.1 是中国 AI 创业公司 DeepSeek 于 2025 年 8 月低调发布的最新旗舰级开源大模型,凭借 6850 亿参数、混合专家(MoE)架构和高度开放的 MIT 授权,迅速引发全球开发者和行业关注。V3.1 主打高效推理、强大编码与数学能力,以及极低的商业使用成本,成为开源 AI 领域的标杆之一,并直接对标 GPT-5、Claude 4.1 等闭源主流模型。
要点梳理
1. 技术与架构
- 模型规模与架构:
- 6850 亿参数(模型卡是 685B,但是详情写着 671B,MoE 混合专家架构,每次推理仅激活 37 亿参数),大幅节省推理与训练算力。
- 支持 128K 超长上下文,满足长文档、多轮会话及代码分析需求。
- 提供 BF16、FP8、F32 等多格式权重优化,适配多样硬件。
- 支持标准聊天模式,以及“思考/工具调用”特殊 token 混合推理模式, 也就是将 V3 和 R1 统一了,后续官方 API 不再提供 V3 和 R1,DeepSeek Chat 变为 V3.1 关闭 thinking 模式,而 Reasoner 变为 V3.1 开启 thinking 模式。
2. 性能表现
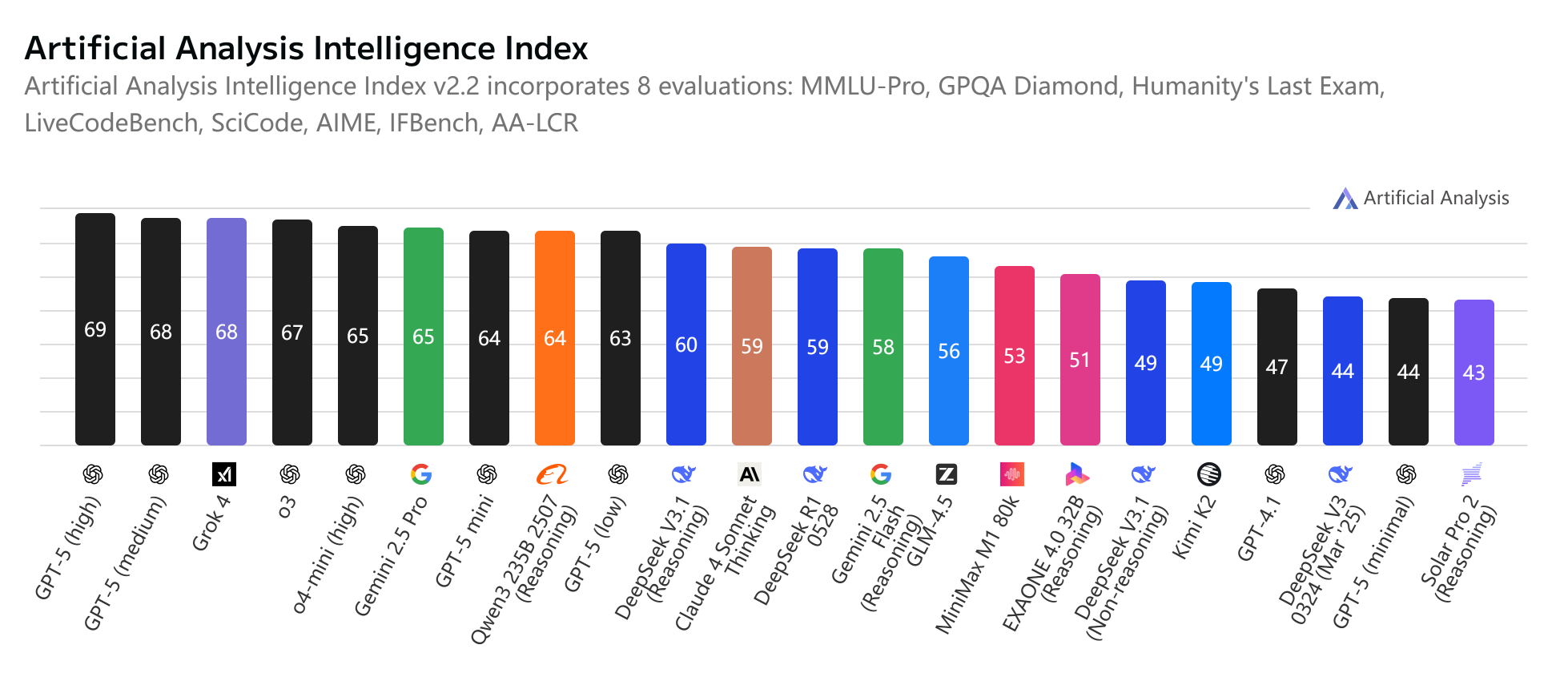
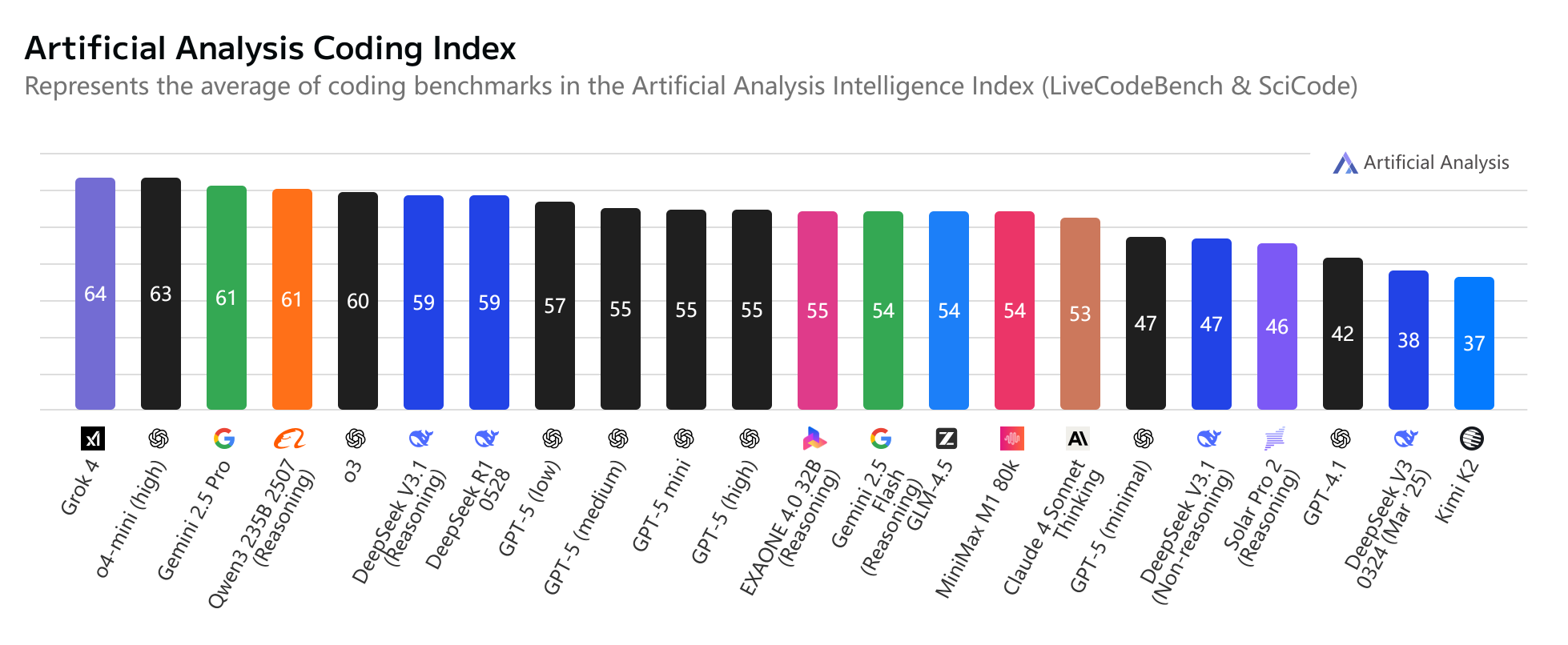
图来自: Artificial Analysis
与之前 v3 和 r1 相比,DeepSeek v3.1 在关闭 thinking 的情况相比 v3 有不少提升,但是启用 thinking 模式后,和 R1 总体相差不大。
- 编程与数学能力突出:
- Aider 编程基准通过率达 71.6%,超越 Claude Opus 4,接近甚至部分超越 GPT-5,代码生成、调试、重构等方面表现出色。(参考: Deepseek v3.1 scores 71.6% on aider – non-reasoning sota)
- dirname: 2025-08-19-17-08-33--deepseek-v3.1
test_cases: 225
model: deepseek/deepseek-chat
edit_format: diff
commit_hash: 32faf82
pass_rate_1: 41.3
pass_rate_2: 71.6
pass_num_1: 93
pass_num_2: 161
percent_cases_well_formed: 95.6
error_outputs: 13
num_malformed_responses: 11
num_with_malformed_responses: 10
user_asks: 63
lazy_comments: 0
syntax_errors: 0
indentation_errors: 0
exhausted_context_windows: 1
prompt_tokens: 2239930
completion_tokens: 551692
test_timeouts: 8
total_tests: 225
command: aider --model deepseek/deepseek-chat
date: 2025-08-19
versions: 0.86.2.dev
seconds_per_case: 134.0
total_cost: 1.0112
costs: $0.0045/test-case, $1.01 total, $1.01 projected
- 数学推理与复杂逻辑题解答能力强(如 AIME、MATH-500 等大规模公开基准表现优异)。
- 文本理解和知识问答基准(如 MMLU)也接近 GPT-4、Claude 3 等顶级模型。
- 推理与通用能力提升:
- 聊天、代码、推理三能力合一,消除了多模型切换复杂性,提升开发及部署效率。
3. 价格与开放性
- 极低使用成本:
- API 调用价格约为$0.56/百万输入 Token,$1.68/百万输出 Token(2025 年 9 月起),同等工作量下比闭源模型便宜 90%以上。
- 典型编程任务成本约$1(对比 Claude Opus 4 为$68,GPT-4/5 约$56-$70),大幅节省企业及开发者 AI 开支。
- MIT 开源协议:
- 免费商用、可二次开发定制与再分发,极大方便创新与产业落地。
- 模型权重可于 Hugging Face 等平台直接下载,亦支持 API 按需调用,但本地布署模型对算力有极高要求(约需 700GB 存储)。
4. 功能与应用场景
- 支持长文档内容处理、企业级批量代码生成/审查、教育编程助教、科研数据分析等众多场景。
- native 工具调用、搜索注入及代码 Agent 等功能,为研发与自动化提供丰富支撑。
- 灵活集成多种开发环境,包括 VSCode、JetBrains IDE、Aider 命令行工具及多类 CI/CD 流程。
- 当前 DeepSeek 官网已经支持 anthropic 格式的 API,可以直接将 DeepSeek 用于 Claude Code。
5. 竞品对比及价值定位
-
与 GPT-5/Claude 4.1 对比:
- 性能接近/略优于 Claude 4 系列,推理能力和开放性优于 GPT-5 的闭源 API。
- 价格占绝对优势,适合大规模调用与创新型开发;闭源模型在生态、安全、合规等企业级深度应用上仍具优势。
- DeepSeek-V3.1 更适合预算敏感、追求自定义与极限性价比的开发者、初创企业及科研机构。
-
缺点与限制:
- 模型体积巨大,本地私有部署算力门槛高,对个人用户不够友好。
- 西方市场在安全审查、地缘政治等因素下采纳速度存在现实障碍。
- 某些超复杂推理、精细领域多模态任务仍略逊于顶级闭源模型。
结论
DeepSeek V3.1 以卓越的性价比、强大的通用与专业能力以及开放包容的授权策略,成为当前开源大模型领域的领军产品。对高频 AI 调用、追求成本控制与创新的团队尤具吸引力,有望推动全球 AI 进一步普惠发展。企业与开发者可根据自身需求权衡生态可用性与模型性能,结合公共 API 或混合部署,自主选择最佳路径。
参考来源
来源声明
本文来自 merchmindai.net。分享或转载本文时,请注明出处,并附上原文链接。
原文链接:https://merchmindai.net/blog/zh/post/deepseek-v3_1-release-summary-features-performance-price



