Claude Opus 4.7 反馈分析:为何发布后口碑两极分化?
Claude Opus 4.7 于 2026 年 4 月 16 日发布。本文结合 Anthropic 官方说明、Reddit 与 Hacker News 讨论,梳理它的能力升级、负面反馈与背后的成因。

2026 年 4 月 16 日,Anthropic 发布了 Claude Opus 4.7。官方给它的定位非常明确:这是目前“最强的通用可用模型”,重点强化复杂推理、长时程代理任务、知识型任务、视觉理解和记忆能力。与此同时,Anthropic 还同步更新了 Claude Code、API 参数和迁移文档,明显希望把 Opus 4.7 推成新一代默认高端模型。
但发布后的第一波社区反馈并不平静。尤其在 Claude Code 重度用户、API 用户和 Hacker News 开发者讨论里,Opus 4.7 很快出现了明显的两极化评价:一部分人认为它是一次实打实的升级,另一部分人则认为它“更爱自信地下结论”“更消耗 token”“需要更多调参”,甚至怀疑它在实际工作中比 4.6 更难用。
本文参考 Anthropic 官方发布页、Claude API 文档,以及截至 2026 年 4 月 18 日可查阅的 Reddit 与 Hacker News 讨论。社区观点本身不是严格意义上的基准测试,但很适合用来观察一款模型在真实工作流中的首轮体感。
作为背景延伸,可参考 Anthropic 点名“蒸馏攻击”后,社区为何吵翻了?;如果需要横向比较另一家厂商的新编码模型发布叙事,也可对照 GPT-5.3-Codex 发布解读:能力升级、基准成绩与落地建议。
核心判断是:Claude Opus 4.7 更像一次“上限更高,但迁移成本也更高”的升级,而不是一次简单的全面成功或明显失利。 官方和一部分重度用户看到的是它在长任务、复杂工程、视觉输入上的提升;另一部分用户感受到的,则是更强的字面执行、更高的 token 消耗,以及一旦出错就更难忍受的“自信型错误”。
这也是整篇文章最核心的判断:口碑分裂不是因为大家在看不同模型,而是因为大家在用同一个模型做不同类型的工作,并且对默认行为变化的容忍度完全不同。
Claude Opus 4.7 实际上改了什么?
如果把所有发布材料压缩成几条真正影响体验的变化,重点其实只有三组。
第一组是能力定位。Anthropic 把 Opus 4.7 明确推向 long-horizon agentic work,也就是更强调连续执行多步任务、在长上下文中维持目标、工具出错后继续推进。这也是为什么官方案例和合作方评价几乎都在讲“更完整地做完任务”,而不是只讲聊天质量。
第二组是输入与工作范围。API 文档把它描述为首个支持更高分辨率图像输入的 Claude 模型,明显在为截图理解、文档识别、计算机操作这类场景铺路。换句话说,Anthropic 想卖的不是一个更会聊天的 Opus,而是一个更适合放进工作流里的 Opus。
第三组是最容易被低估的部分:默认行为变了。 这次更新不只加了能力,也改了交互契约。根据官方文档,Opus 4.7 引入 xhigh effort,移除了旧的 extended thinking budgets,改成只保留 adaptive thinking,默认隐藏 thinking summary,而且新 tokenizer 会让部分文本场景的 token 消耗上升。更重要的是,Anthropic 还明确写到它会更字面地执行指令、在低 effort 下更少自行泛化、默认更少调用工具。
这意味着很多用户以为自己只是在升级模型,实际上是在升级一整套默认工作方式。只要这一点没意识到,后面的口碑分裂几乎是必然的。
为什么官方很乐观,但用户会觉得“退步”?
因为官方和用户衡量的根本不是同一件事。
Anthropic 的叙事非常稳定:Opus 4.7 在编码、长任务、视觉、记忆和知识工作上都比 4.6 更强,合作方评价也几乎一边倒地强调“更可靠、更完整、更少工具错误”。这个口径主流媒体大体也接受了,但不是毫无保留地接受。VentureBeat 的总结就很典型:它承认 Opus 4.7 很强,但也强调这不是全面碾压,而更像在特定高价值任务上重新拉回领先。
与此同时,The Verge 和 Tom's Guide 的切入点又提醒了另一件事:Anthropic 这次发布并不只是能力更新,也是一次安全产品化叙事。Opus 4.7 被放在一个“比 Mythos Preview 更适合公开交付”的位置上,这会自然影响它的风格、边界和默认行为。换句话说,一部分用户感觉它更拘谨、更保守,并不完全是错觉。
这种微妙变化,在一些开发者的第一手观察里也能看到。
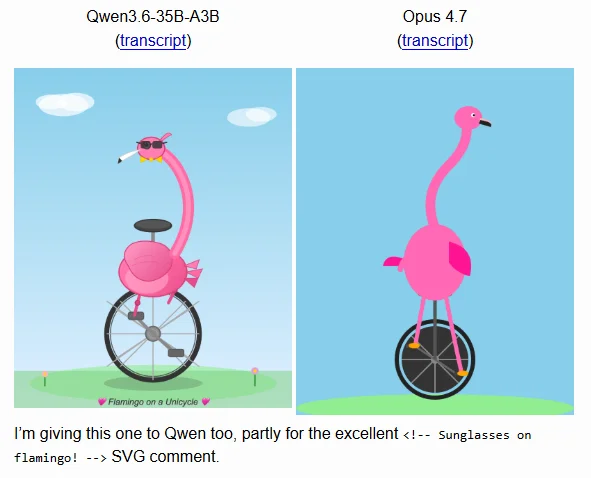 <small>Simon Willison的SVG测试</small>
<small>Simon Willison的SVG测试</small>
问题在于,一线用户不会先从产品策略理解这些变化,他们只会从自己的工作流感知它是不是更顺手。所以官方看到的是“完成率更高”,用户先感受到的却可能是“以前不用交代得这么细,现在为什么必须写得这么细”。
这次负面反馈真正集中在哪?
把 Reddit、HN 和媒体报道放在一起看,抱怨其实高度收敛,主要就集中在四个点。
1)最伤信任的不是犯错,而是“自信地错”
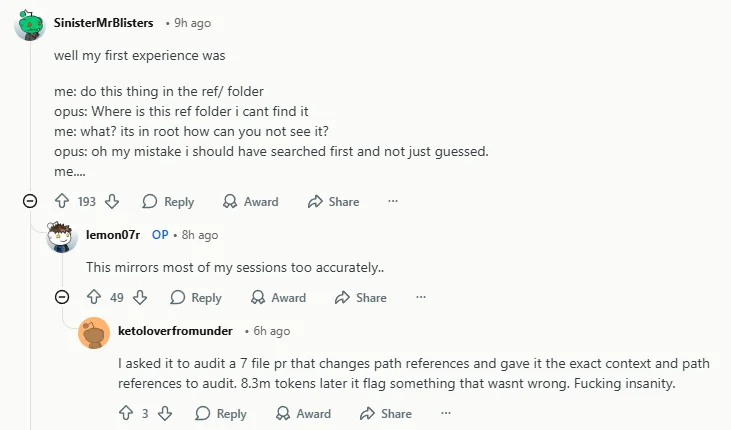
Reddit 上那条传播极快的帖子之所以引发共鸣,不是因为它只是在说 4.7 不够聪明,而是因为它抓住了一个更让工程用户难受的问题:模型会假设不存在的信息、没有先核实证据、被纠正后还继续坚持自己的解释。Business Insider 把这类情绪扩散写成 “Claude-lash”,说明这已经不只是单个社区的抱怨,而是开始变成公共口碑问题。
对重度编码用户来说,普通错误还能接受,“没查清楚就很笃定” 才最伤信任,因为这直接增加审查成本。
2)它更挑指令写法,也更挑 effort
这波反馈里还有一个很明显的共识:4.7 不是不能用,而是比 4.6 更挑使用方式。Reddit 和 HN 里同时存在两种声音,一种说它“明显退步”,另一种说在 Claude Code、长上下文、high 或 xhigh effort 下反而更稳。这两种说法并不矛盾,反而说明问题很可能就出在默认行为变化上。
Anthropic 文档已经把这点写得很清楚:它更 literal,更少自动泛化,建议在 coding 和 agentic 场景用更高 effort。换言之,过去仅凭模糊描述也能推进的流程,如今更容易因为指令不够具体而中途失效。
3)成本上升比能力提升更容易被感知
新 tokenizer、adaptive thinking、更高 effort,这些东西叠在一起之后,最先被用户注意到的往往不是“任务完成率”,而是 token 账单、响应延迟和返工次数。只要用户没有明显感受到“更贵换来更省心”,关于 4.7 的负面印象就会迅速放大。
所以争议的重点从来都不是“token 为什么变多”,而是“多出来的这些 token,到底有没有换来更少的人类监督”。
4)模型问题和产品问题被混在了一起
很多 HN 用户真正不满的,未必只是模型本身,而是 Claude Chat、Claude Code、连接器、托管环境、CLI、API 参数、订阅体系这些东西叠在一起之后,可观察性和一致性都变差了。用户很难判断某次失败究竟是模型退步、输入方式不对、effort 不够,还是某个产品层面的默认设置变了。
一旦问题定位变难,用户就会把所有摩擦都记到模型头上。这也是为什么同一版本会同时被描述成“更强”与“更糟”。
为什么这次争议会被放大?
除了模型本身的变化,还有两个背景因素在放大情绪。
第一,这波不满不是从 4.7 发布当天才开始的。 在发布前,VentureBeat、The Register、InfoWorld 等媒体已经在跟进一轮关于 Claude Code 是否“变笨”或被 nerf 的争议。也就是说,Anthropic 是在一个已经存在“回退焦虑”的舆论环境里发布新模型的,用户天然会更敏感。
第二,开发者对 Claude 的期待本来就和普通聊天模型不同。Claude Code 这批核心用户并不只是问问题,他们拿它改代码、读日志、修 bug、跑长链路任务,所以他们对“会不会主动核查”“会不会读完文件”“错了之后会不会马上改”极其敏感。一次版本更新如果在这些点上有波动,负评会比普通聊天产品猛烈得多。
这也是为什么 Simon Willison 那类看似轻松的小测试也有参考价值。它未必能证明 4.7 整体更差,但它提醒我们:一次升级哪怕在大 benchmark 上更好,也可能在用户最容易第一时间感知的小任务上露出短板。
那么,这些负面评论到底成立吗?
我的判断是:成立,但不能被粗暴概括为“Opus 4.7 失败”。
成立的部分在于,确实有一批重度用户在发布后第一时间感受到了明显退步,尤其是幻觉、自信错误、默认设置不稳、成本上升这些问题,而且这些抱怨并不是零散孤例。Reddit、HN、Business Insider 乃至更早的“nerf”争议,都在互相印证这一点。
不能简单把它定义为失败的原因在于,另一批用户同样给出了正面反馈,尤其是在 Claude Code、长上下文、长时程任务和高 effort 场景里。换句话说,4.7 更像是把模型能力和使用门槛一起抬高了。如果愿意重新校准工作流,它可能比 4.6 更强;如果期待无缝升级,它就很可能显得更差。
如果要评估是否值得升级,可以怎么做?
如果目标不是追逐短期热度,而是判断它值不值得进入日常工作流,那么至少应做一轮小规模对照测试。
1)不要只测单轮效果,要测返工成本
很多模型在单轮演示里很好看,但真正决定效率的是:
- 它有没有主动核查事实;
- 被纠错后会不会尽快修正;
- 会不会反复犯同一类错误;
- 一个任务从开始到验收需要你插手几次。
这比“第一轮回答看起来多聪明”更重要。
2)分开测默认模式和高 effort 模式
鉴于 4.7 的行为明显受 effort 影响,建议至少对比:默认设置、high、xhigh 三种模式。否则很容易把“配置问题”误判成“模型整体退步”,或者把“高成本模式下的提升”误判成“所有情况下都更好”。
3)单独记录 token 与延迟
Opus 4.7 的争议有相当一部分来自成本感知。如果你只看任务成败,不看 token、时延和返工次数,就很难得出对团队真正有意义的结论。
4)检查是否仍在沿用 4.6 的旧习惯
如果过去习惯让 Claude “自己补齐意图”,现在就要特别注意指令写法是否仍然过度依赖这种风格。4.7 更字面、更克制时,往往需要把“先检查哪些文件”“先验证再下结论”“不要脑补缺失配置”写得更清楚。
这确实增加了使用门槛,但很可能就是当前版本的现实约束。
总结
Claude Opus 4.7 的发布,并不是一次简单的“参数更大、分数更高”的版本更新,而是一次明显面向代理式工作流的模型重构。官方叙事强调的是:它更擅长长任务、更可靠、更会看图、更能记忆、更适合工程代理。
但社区在发布后的真实反馈提醒我们另一面:当模型默认行为、tokenizer、thinking 模式、可见性和产品配置体系一起变化时,哪怕客观能力上升,用户也完全可能在第一时间感受到更高的摩擦、更差的可控性和更强的不信任。
所以,Opus 4.7 当前更准确的评价或许不是“神作”或“翻车”,而是:它像一个上限更高、但默认更挑环境和方法的新版本。 如果愿意重新调教工作流,它可能比 4.6 更强;如果期待无缝升级,它也可能带来明显落差。
这也是这波负面评论真正值得重视的地方。它们不只是情绪宣泄,而是在提醒所有模型厂商:前沿模型的发布,不能只靠 benchmark 和合作伙伴证词,还要认真处理迁移成本、默认配置和用户可观察性。
相关资源
- Anthropic 官方发布:Introducing Claude Opus 4.7
- Claude API Docs: What's new in Claude Opus 4.7
- Claude API Docs: Migration guide
- Reddit:Opus 4.7 is legendarily bad. I cannot believe this.
- Hacker News:Claude Opus 4.7(id=47793411)
- Business Insider:The Claude-lash is here: Opus 4.7 is burning through tokens and some people's patience
- VentureBeat:Anthropic releases Claude Opus 4.7, narrowly retaking lead for most powerful generally available LLM
- The Verge:Anthropic releases a new Opus model amid Mythos Preview buzz
- Tom's Guide:Anthropic just released Opus 4.7 — the 'civilian' version of the AI they said was too dangerous for us
- Simon Willison:Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
- VentureBeat:Is Anthropic 'nerfing' Claude? Users increasingly report performance degradation as leaders push back
- The Register:AMD's AI director slams Claude Code for becoming dumber and lazier since last update
来源声明
本文来自 merchmindai.net。分享或转载本文时,请注明出处,并附上原文链接。
原文链接:https://merchmindai.net/blog/zh/post/claude-opus-4-7-feedback-analysis



