DeepSeek V4プレビュー公開: 100万トークン文脈、Flash/Pro、新API価格を整理
2026年4月24日時点で、DeepSeekはDeepSeek V4シリーズをAPIドキュメントとHugging Faceで公開しています。本記事では、Flash/Proの2モデル、100万トークン文脈、Thinking Mode、API価格、公開ウェイトの情報を整理します。

2026年4月24日 時点で、DeepSeekは DeepSeek V4 シリーズを公式APIドキュメントとHugging Face上で公開しています。Hugging Faceのモデルカードによると、この世代は現時点で preview version と位置づけられています。現段階で公開されている情報を見ると、API側では deepseek-v4-flash と deepseek-v4-pro の2つのモデル名が用意され、あわせてFlash / ProのBaseおよびInstructウェイトも公開されています。
すでに公開され、直接確認できる情報を整理すると、DeepSeek V4の主な更新点は4つです。100万トークンのコンテキスト、デフォルトで有効なThinking Mode、Flash/Proの2層構成、そして公開済みのAPI価格 です。これらは、そのまま接続方法、能力の上限、運用コストに関わる情報でもあります。
実際に何が公開されたのか
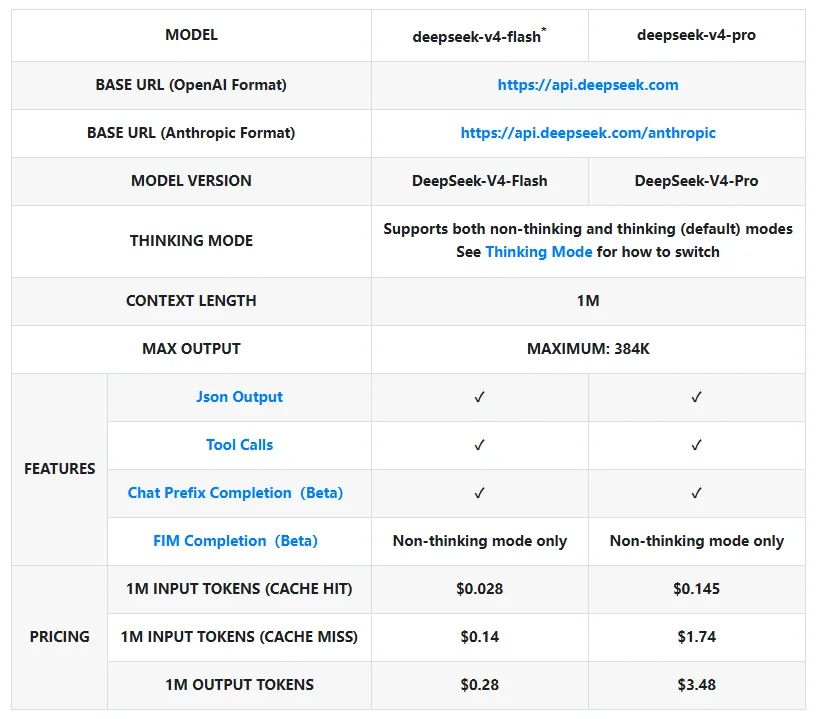
DeepSeek APIドキュメントの「Models & Pricing」ページによると、現在公開されているV4のAPIモデルは次の2つです。
deepseek-v4-flashdeepseek-v4-pro
ドキュメントでは、両モデルとも OpenAI互換 と Anthropic互換 の形式で利用できるとされています。両者とも Thinking Mode に対応しており、しかもデフォルトで有効です。コンテキスト長はどちらも 100万トークン、最大出力長は 384Kトークン です。さらに、JSON Output、Tool Calls、プレフィックス継続生成(Beta)はV4で利用可能で、FIM Completion (Beta) はThinking Modeを無効にした場合のみ利用できます。
このことから、DeepSeek V4はもはや研究段階の名称にとどまらず、実際に利用できるAPI製品 の段階に入っていることが分かります。
Thinking Modeはデフォルト有効、旧モデル名は段階的に廃止へ
DeepSeekのThinking Modeドキュメントでも、この点はかなり明確に説明されています。V4では主に次の2つの制御が公開されています。
thinking.enabled / disabledでThinking Modeの切り替えreasoning_effortで推論強度を調整。公開ドキュメントではhighとmaxを掲載
ドキュメントには、Thinking Modeはデフォルトで有効 と書かれています。通常リクエストの既定値は high で、一部の複雑なエージェント系リクエストでは自動的に max へ引き上げられる場合があります。互換性の扱いとしては、low と medium は high に、xhigh は max にマッピングされます。
もうひとつ重要なのが、互換モデル名の整理です。DeepSeekは価格ページで、deepseek-chat と deepseek-reasoner を将来的に廃止予定としています。互換性のため、現時点ではそれぞれ deepseek-v4-flash の非Thinking ModeとThinking Mode に対応づけられています。旧モデル名を前提に組み込んでいるチームは、この移行に注意が必要です。
Hugging Faceではすでに4つの公開リポジトリが並んでいる
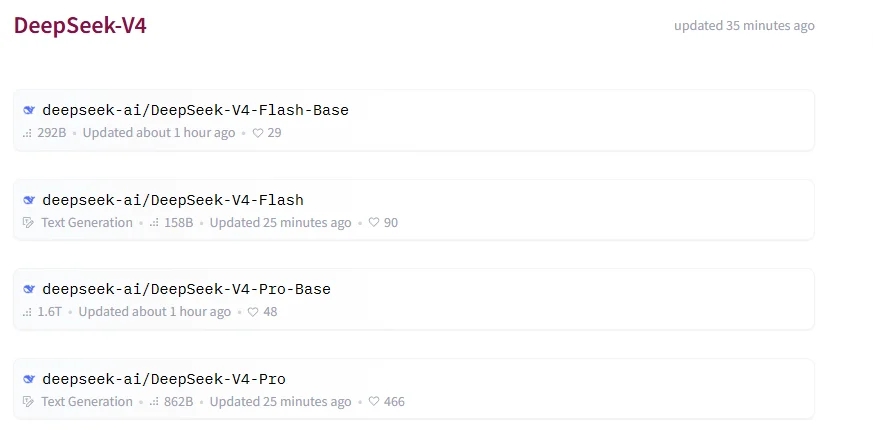
執筆時点で、DeepSeekの DeepSeek-V4 コレクションには、すでに次の4つのリポジトリが公開されています。
DeepSeek-V4-Flash-BaseDeepSeek-V4-FlashDeepSeek-V4-Pro-BaseDeepSeek-V4-Pro
DeepSeek-V4-Pro の公式モデルカードには、次の仕様が掲載されています。
| モデル | 総パラメータ数 | 有効化パラメータ数 | コンテキスト長 | 精度 |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
モデルカードでは、V4は2つの Mixture-of-Experts(MoE) 言語モデルとして説明されており、ProとFlashの両方が100万トークン級のコンテキストに対応するとされています。自前運用やローカル展開を検討するチームにとって重要なのは、V4がAPI専用ではなく、ウェイト自体もすでに公開されている点です。
さらにモデルカードには、これらのリポジトリとウェイトが MIT License で公開されていることも明記されています。DeepSeekは encoding と inference のディレクトリも公開しており、メッセージ形式、ウェイト変換、ローカル実行方法について説明しています。
API価格はすでに公開済みで、FlashとProの差もはっきりしている
現在の価格ページでは、DeepSeek V4の価格帯はかなり分かりやすく分かれています。
| モデル | 入力価格(キャッシュヒット) | 入力価格(キャッシュミス) | 出力価格 |
|---|---|---|---|
| deepseek-v4-flash | 0.2元 / 100万トークン | 1元 / 100万トークン | 2元 / 100万トークン |
| deepseek-v4-pro | 1元 / 100万トークン | 12元 / 100万トークン | 24元 / 100万トークン |
この価格表から見ると、Flashはコスト効率重視で大量呼び出し向け、Proは単価の高い上位モデル という位置づけがかなり明確です。大量生成、軽量Q&A、構造化抽出が中心ならFlashのほうがコストを抑えやすく、より重い推論、長文文脈の品質、高難度のagentタスクを重視するなら、Proの価格が高性能帯の目安になります。
モデルカードから追加で確認できる技術情報
Hugging Faceのモデルカードには、次のような技術情報も掲載されています。
- DeepSeek V4は
CSAとHCAを組み合わせたハイブリッド注意機構を採用 - DeepSeekによると、DeepSeek-V3.2と比べて、V4-Proは100万文脈設定で1トークンあたりの推論FLOPsを27%、KV cacheを10%まで削減
mHC(Manifold-Constrained Hyper-Connections)を導入- 学習には
Muonオプティマイザを使用 - 事前学習データは 32T tokens超
これらはDeepSeek自身のモデルカードと技術資料に基づく説明ですが、少なくとも公開情報を見る限り、今回のリリースは単なるバージョン更新ではなく、新しいアーキテクチャと学習方針もあわせて打ち出したものだと分かります。
Evaluation Resultsは何を示しているのか
DeepSeek-V4-Pro のモデルカードには、DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base、DeepSeek-V4-Pro-Base を比較したベースモデル評価も掲載されています。この表から読み取りやすいのは、V4-Pro-Baseが知識系タスク、長文コンテキスト系ベンチマーク、そして一部の難しめの事実QAで明確に伸びている という点です。
代表的な結果をいくつか挙げると、次の通りです。
| Benchmark | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|
| MMLU-Pro (EM) | 65.5 | 68.3 | 73.5 |
| MultiLoKo (EM) | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 28.3 | 30.1 | 55.2 |
| FACTS Parametric (EM) | 27.1 | 33.9 | 62.6 |
| HumanEval (Pass@1) | 62.8 | 69.5 | 76.8 |
| LongBench-V2 (EM) | 40.2 | 44.7 | 51.5 |
この表からは、3つの流れが見えてきます。
第一に、V4-Pro-Baseは前世代より知識系の強さがかなり増している ことです。Simple-QA verified や FACTS Parametric のような、事実知識やパラメトリック知識に寄ったベンチマークでは、V3.2-Baseに対する伸びが大きく、DeepSeekが打ち出す知識能力向上は少なくとも公開ベンチマーク上で確認できます。
第二に、長文コンテキスト性能の向上は単発ではなく、全体設計の一部として現れている ことです。LongBench-V2 は40.2から51.5まで伸びており、モデルカード内の100万文脈効率に関する説明と合わせて見ると、今回のV4で長文処理が重要テーマになっていることが分かります。
第三に、FlashとProの役割の違いも表に出ている ことです。Flash-Baseは単なる廉価版ではなく、すでに複数の知識タスクやコードタスクでV3.2-Baseを上回っています。ただし、知識QA、難度の高い試験系ベンチマーク、長文コンテキストでは、Pro-Baseのほうがより高い上限を示しています。
もちろん、ここには前提もあります。この Evaluation Results はあくまでベースモデル同士の公式比較であり、実際の製品利用体験をそのまま保証するものではありません。 特にV4ではThinking Modeやreasoning effortがAPI側の挙動に直結しているため、実使用時の品質は推論予算や設定によって変わり得ます。
DeepSeek-V4-Pro-Max vs Frontier Modelsは何を意味するのか
モデルカードには、より注目されやすい比較表として DeepSeek-V4-Pro-Max vs Frontier Models も掲載されています。ここでは DS-V4-Pro Max が、Opus-4.6 Max、GPT-5.4 xHigh、Gemini-3.1-Pro High、K2.6 Thinking、GLM-5.1 Thinking といったクローズド系フロンティアモデルと並べて比較されています。
代表的な行を抜き出すと、次のようになります。
| Benchmark | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 84.4 |
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | 3206 |
| MRCR 1M (MMR) | 92.9 | - | 76.3 | 83.5 |
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.6 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 51.8 |
この表を一文で要約するなら、DeepSeek-V4-Pro-Maxは、コードや一部のツール利用・エージェント系タスクではすでに非常に競争力が高く、項目によっては主要なクローズドモデルを上回る一方、最難関の総合知識や極限推論ベンチマークで全面的に首位に立ったわけではない ということになります。
ここからは、大きく4つのポイントが見えてきます。
第一に、DeepSeekはこのモデルをオープンモデル第一梯隊に置きたい意図が明確 だということです。モデルカードでも DeepSeek-V4-Pro-Max を「現在最良のオープンソースモデル」と表現しています。少なくとも LiveCodeBench、Codeforces、MCPAtlas Public のようなコード・ツール系ベンチマークでは、その主張に一定の根拠があります。
第二に、あらゆる軸でクローズド最前線モデルに並んだわけではない という点です。MMLU-Pro、GPQA Diamond、HLE、Apex のような、総合知識、研究寄り推論、超高難度問題に近いベンチマークでは、Gemini-3.1-Pro High や GPT-5.4 xHigh のほうが依然として上限の高さを見せています。つまりV4-Pro-Maxは、「全面的に逆転した」というより、「差を大きく縮めた」と見るほうが正確です。
第三に、現時点で特に目立つのは、コードとエンジニアリング実務寄りワークフローの強さ です。LiveCodeBench 93.5、Codeforces 3206、さらに SWE Verified 80.6、Terminal Bench 2.0 67.9 という並びを見ると、DeepSeekは今回、試験型ベンチマークだけでなく、コーディング、ターミナル操作、agent workflowにおける実用性も強く打ち出していることが分かります。
第四に、長文コンテキストと中国語知識は差別化ポイントとして重要 です。Chinese-SimpleQA の84.4はかなり高い水準であり、MRCR 1M や CorpusQA 1M からも、100万トークン文脈が単なる仕様表の数字ではないことがうかがえます。長文ドキュメント処理、中国語QA、ローカル知識ワークフローを重視するチームにとっては、一般的なベンチマーク順位以上に意味のある情報です。
ただし、ここでも前提は必要です。この比較表もモデルカード内の公式比較であり、ベンダー間で評価設定、推論予算、ツール構成が完全に揃っているとは限りません。 したがって、より妥当な読み方は「DeepSeekが全面制覇した」というものではなく、オープンモデルとクローズド最前線モデルの差を、多くのチームが本格評価したくなる水準まで縮めた と捉えることです。
現時点でかなり明確になっていること
現時点で公開されている公式情報から、少なくとも次の点はかなり明確です。
- DeepSeek V4はすでに利用可能な段階に入っている。APIドキュメント、価格ページ、Hugging Faceリポジトリがすべて公開済みです。
- この世代は少なくともFlashとProの2層構成になっている。しかもAPI提供と公開ウェイトの両方がそろっています。
- 100万トークン文脈とThinking ModeはV4の中核的な特徴 であり、単一モデルだけの付加機能ではありません。
- 旧来の
deepseek-chat/deepseek-reasoner命名は段階的に終了へ向かっている。移行先はすでにV4系に定まりつつあります。
中国発LLMの更新スピードを追っている読者にとって、このリリースの意味は比較的明快です。DeepSeekはV4を、単なる次世代コードネームではなく、ドキュメント、API、価格、ウェイトが同時に公開された実製品フェーズ に進めました。今後の注目点は、実運用での品質、第三者デプロイ環境の整備、そして開発者コミュニティの実使用レポートに移っていくはずです。
関連リンク
出典について
この記事は merchmindai.net に掲載された内容です。共有または転載する場合は、出典と元記事のリンクを明記してください。
元記事リンク:https://merchmindai.net/blog/ja/post/deepseek-v4-release-api-pricing-open-weights



