DeepSeek V3.1リリース概要:パフォーマンス、価格、機能のハイライト
DeepSeek V3.1リリースの主なパフォーマンス、価格、および機能のハイライトを簡単にまとめ、同種の主要な大規模モデルと比較します。

概要
DeepSeek V3.1 は、中国の AI スタートアップ DeepSeek が 2025 年 8 月にひっそりとリリースした最新のフラッグシップオープンソース大規模モデルです。6850 億パラメータ、混合専門家(MoE)アーキテクチャ、高度にオープンな MIT ライセンスを特徴とし、世界中の開発者や業界の注目を迅速に集めました。V3.1 は高効率な推論、強力なコーディング・数学能力、そして極めて低コストな商用利用を強みとし、オープンソース AI 分野の基準の一つとなり、GPT-5 や Claude 4.1 などのクローズドソース主流モデルと直接対抗しています。
主要ポイントまとめ
1. 技術とアーキテクチャ
- モデル規模とアーキテクチャ:
- 6850 億パラメータ(モデルカードでは 685B ですが、詳細は 671B、MoE 混合専門家アーキテクチャにより推論時はわずか 37 億パラメータのみが活性化)、推論と学習の計算リソースを大幅に節約。
- 128K の超長コンテキストをサポートし、長文、多ターン会話、コード解析のニーズに対応。
- BF16、FP8、F32 など複数フォーマットの重み最適化を提供し、多様なハードウェアに対応。
- 標準チャットモードに加え、「思考/ツール呼び出し」特殊トークンの混合推論モードをサポート。つまり V3 と R1 を統合し、今後公式 API では V3 と R1 の区別はなく、DeepSeek Chat は V3.1 の thinking モードをオフ、Reasoner は V3.1 の thinking モードをオンで使用します。
2. パフォーマンス
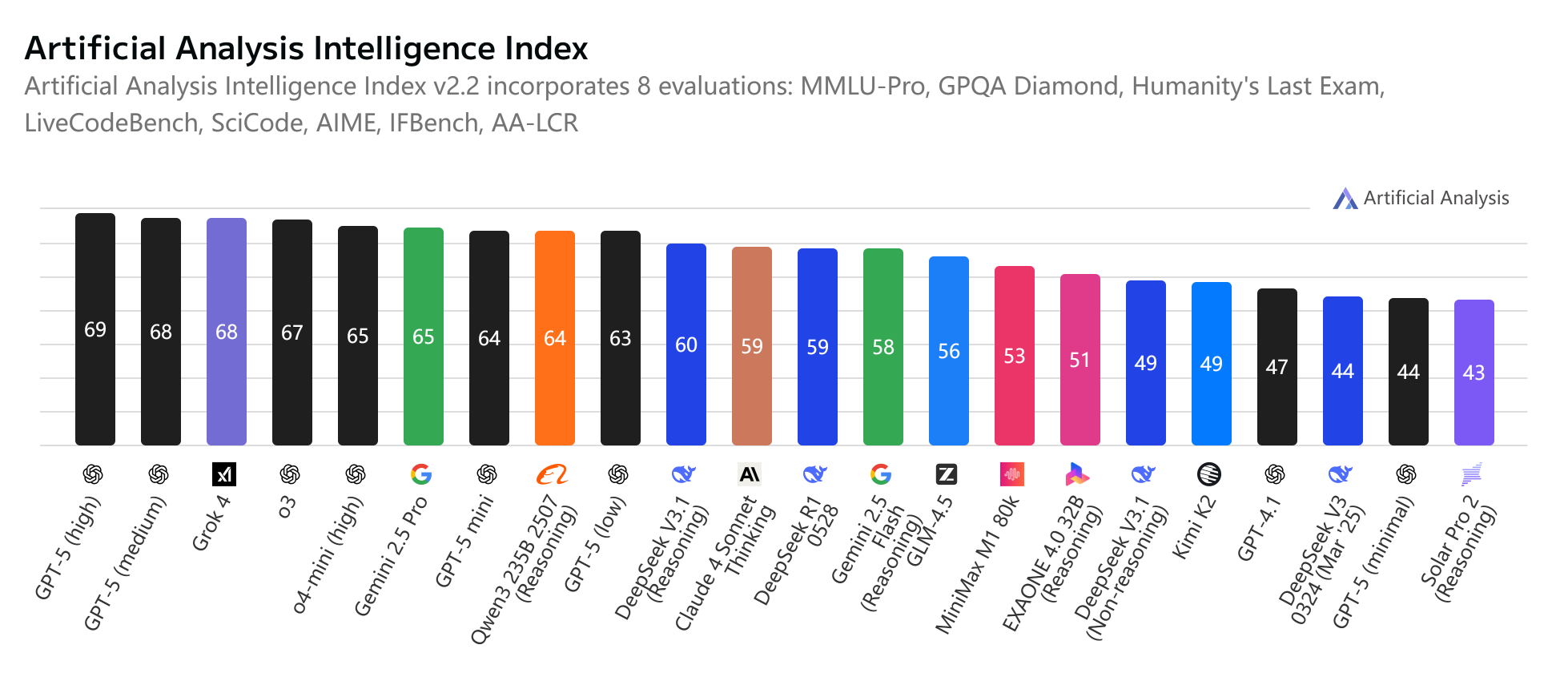
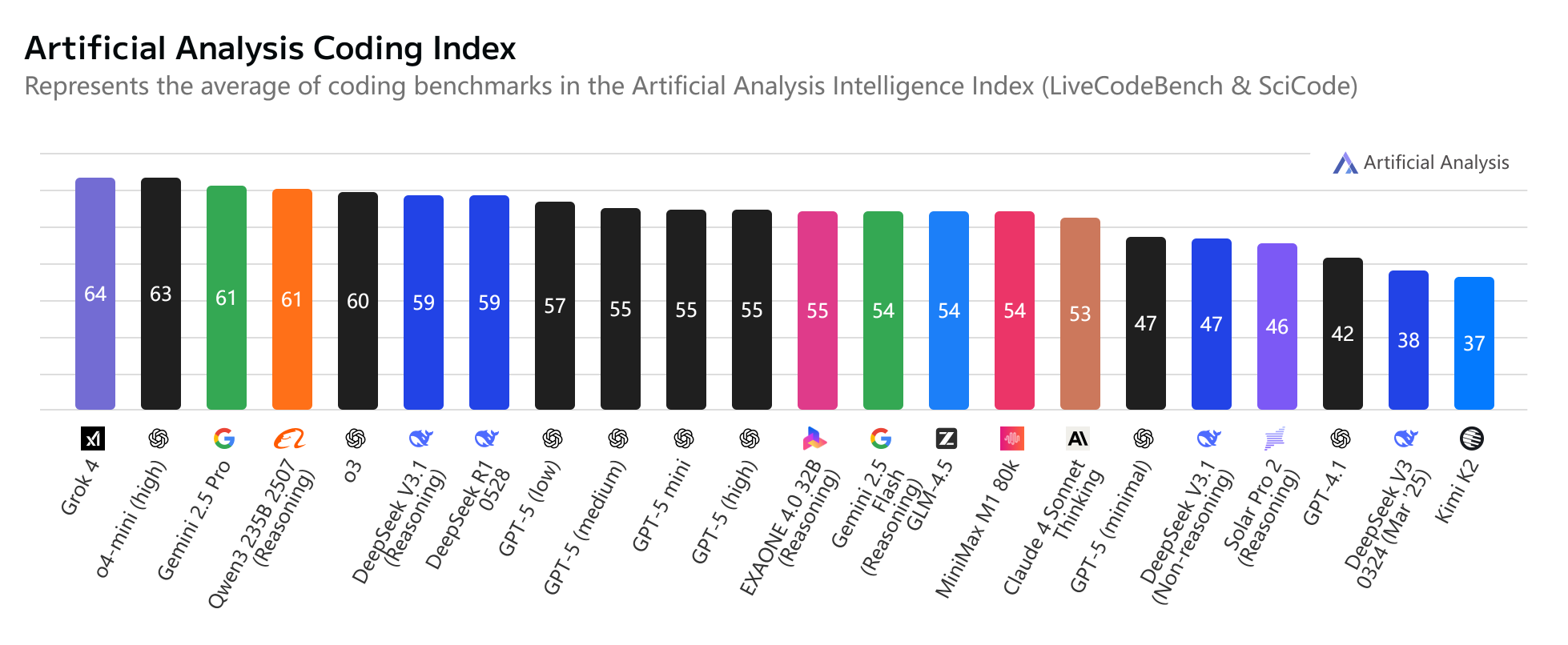
画像出典: Artificial Analysis
以前の v3 および r1 と比較して、DeepSeek v3.1 は thinking モードをオフにした状態で v3 よりも大幅に向上していますが、thinking モードを有効にすると R1 とほぼ同等の性能を示します。
- プログラミングと数学能力が卓越:
- Aider プログラミングベンチマークの合格率は 71.6%で、Claude Opus 4 を超え、GPT-5 に近いか一部ではそれを超えています。コード生成、デバッグ、リファクタリングなどで優れたパフォーマンス。(参考: Deepseek v3.1 scores 71.6% on aider – non-reasoning sota)
- dirname: 2025-08-19-17-08-33--deepseek-v3.1
test_cases: 225
model: deepseek/deepseek-chat
edit_format: diff
commit_hash: 32faf82
pass_rate_1: 41.3
pass_rate_2: 71.6
pass_num_1: 93
pass_num_2: 161
percent_cases_well_formed: 95.6
error_outputs: 13
num_malformed_responses: 11
num_with_malformed_responses: 10
user_asks: 63
lazy_comments: 0
syntax_errors: 0
indentation_errors: 0
exhausted_context_windows: 1
prompt_tokens: 2239930
completion_tokens: 551692
test_timeouts: 8
total_tests: 225
command: aider --model deepseek/deepseek-chat
date: 2025-08-19
versions: 0.86.2.dev
seconds_per_case: 134.0
total_cost: 1.0112
costs: $0.0045/テストケース、合計$1.01、予測$1.01
- 数学推論と複雑な論理問題の解答能力に優れ(AIME、MATH-500 などの大規模公開ベンチマークで優秀な成績)。
- テキスト理解と知識質問応答ベンチマーク(MMLU など)でも GPT-4、Claude 3 などトップクラスのモデルに近い性能。
- 推論と汎用能力の向上:
- 会話、コード、推論の三能力を統合し、複数モデル切り替えの複雑さを解消、開発およびデプロイ効率を向上。
3. 価格とオープン性
- 非常に低い利用コスト:
- API 呼び出しは入力 Token100 万あたり約$0.56、出力 Token100 万あたり約$1.68(2025 年 9 月から)、同等の作業量でクローズドソースモデルより 90%以上安価。
- 典型的なプログラミングタスクコストは約$1(Claude Opus 4 は$68、GPT-4/5 は約$56-$70)、企業や開発者の AI 支出を大幅に節約。
- MIT オープンソースライセンス:
- 商用利用無料、二次開発やカスタマイズ、再配布が可能で、イノベーションと産業展開を大きく促進。
- モデルの重みは Hugging Face などで直接ダウンロード可能。また API 経由のオンデマンド利用も可能だが、ローカル展開は約 700GB のストレージなど非常に高い計算リソースが必要。
4. 機能と適用シーン
- 長文コンテンツ処理、企業向け一括コード生成・レビュー、教育向けプログラミングアシスタント、研究データ解析など多様なシーンをサポート。
- ネイティブツール呼び出し、検索インジェクション、コードエージェントなどの機能が研究開発や自動化を強力に支援。
- VSCode、JetBrains IDE、Aider CLI ツール、各種 CI/CD ワークフロー等、多様な開発環境に柔軟に統合可能。
- 現在 DeepSeek 公式サイトは Anthropic フォーマット API をサポートし、DeepSeek を直接 Claude Code に利用可能。
5. 競合製品との比較と価値定位
-
GPT-5/Claude 4.1 との比較:
- 性能は Claude 4 系列に近くやや優勢、推論能力とオープン性においては GPT-5 のクローズド API を上回る。
- 価格は圧倒的に有利で、大規模呼び出しや革新的開発に向く。クローズドモデルはエコシステム、安全性、コンプライアンス面で企業向けに優位性。
- DeepSeek-V3.1 はコスト意識が高くカスタマイズや究極のコストパフォーマンスを求める開発者、スタートアップ、研究機関に適している。
-
欠点と制限:
- モデルサイズが巨大で、ローカルプライベート展開には高い計算リソースが必要で個人ユーザーには使いづらい。
- 西側市場では安全審査や地政学的要因により採用速度に現実的障壁あり。
- 非常に複雑な推論や精細な領域のマルチモーダルタスクでは依然としてトップクローズドモデルに若干劣る。
結論
DeepSeek V3.1 は卓越したコストパフォーマンス、強力な汎用および専門能力、オープンかつ包摂的なライセンス戦略により、現オープンソース大規模モデル分野のリーダー的存在です。高頻度な AI 呼び出し、コスト管理とイノベーションを追求するチームに特に魅力的で、世界の AI 普及と発展を促進すると期待されます。企業および開発者は自身のニーズに応じてエコシステムの利用可能性とモデル性能を比較検討し、パブリック API やハイブリッド展開を組み合わせて最適な道を自主的に選択できます。
参考資料
出典について
この記事は merchmindai.net に掲載された内容です。共有または転載する場合は、出典と元記事のリンクを明記してください。
元記事リンク:https://merchmindai.net/blog/ja/post/deepseek-v3_1-release-summary-features-performance-price



